The 1976 book Algorithms + Data Structures = Programs by Niklaus Wirth suggests that algorithms and data structures are an integral part of programs. Computer scientists can view non-trivial problems as a sequence of story problems. They solve each problem with an algorithm, either a well-known algorithm or one designed specifically for the problem. Every algorithm utilizes data spanning a broad spectrum, ranging from single variables to binary trees to complex databases. The compiler can process single variables, arrays, structures, and classes, but can't directly process more complex organizations without compromising its size and performance. Although the complex structures are inappropriate as language primitives, they are too beneficial to ignore.
The previous examples demonstrate that programmers can create data structures storing data of any type and organize it in numerous ways, but doing so distracts them from the overall problem solution. Consequently, most general-purpose programming languages provide libraries of common and frequently used data structures. The C++ Standard Template Library (STL) provides many common, well-understood, and useful data structures that C++ refers to as containers. As suggested by its name, the STL relies on templates to make the containers general. The following figures present general, high-level views of the STL classes and their operations.
Categories
Sequential
Associative
Orderable
Orderable
Unorderable
Sequential
Associative
Orderable
Unorderable
STL container categories.
The C++ documentation divides containers into two broad categories: sequential and associative. It further divides associative containers into two subcategories: orderable and unorderable. Sequential containers organize their contents linearly, independent of the stored values. Examples include arrays, stacks, queues, dequeues, and heaps. Programs access elements by their position in the structure, such as an index, top, front, back, etc.1
The elements stored in associative data structures typically consist of aggregate data implemented with objects. They organize the elements based on a subset of the element's values or fields, referred to as a key. These structures provide at least one searching function to locate elements with a matching key, allowing the program to access all the associated element data. Binary trees demonstrate an orderable associative structure. A hash function transforms a key into a location in a hash table. A good function evenly distributes data across the table, making the locations appear random and consequently unorderable.
Standard Data Structure Operations
data structure, standard data structure operations, iterator
The previous introduction to binary trees described five broad operation categories that data structures frequently support. The STL containers support these operations under various names. The text illustrates some of the common STL operations with the vector container.
Operation
vector
Comment
Create
vector
Creates an empty vector with capacity for a few elements.
vector(size)
Creates an empty vector with a capacity of size elements. Although vectors can automatically grow to accommodate (practically) an unlimited number of elements, growing is an expensive (time-consuming) operation, so it's more efficient to create such vectors with large capacities initially.
Destroy
~vector()
Destroys the vector and all of the elements it stores.
Insert
push_back(e)
Inserts an element at the end of the vector.
insert(pos, e)
Inserts element e at position pos (specified as an iterator).
Access
operator[](index)
Accesses the element at position index in the vector.
at(index)
The same as operator[] but ensures that index is valid.
front
Accesses the element at the front or beginning of the vector.
back
Accesses the element at the end or back of the vector.
Remove
pop_back
Removes and destroys the last element at the back or end of the vector.
erase
Removes and destroys one or more elements specified by one or two iterators.
clear
Removes and destroys all elements stored in the vector.
A partial list of vector operations.
Vectors organize the data they store linearly, similar to an array. However, unlike an array, they manage their own memory. When a vector needs to grow (when a program adds elements beyond its capacity), it allocates a new, larger array on the heap, copies the existing elements from the old to the new array, and destroys the old array. The figure illustrates some of the various functions implementing the standard data structure operations, while reflecting the vector's sequential organization. Please follow the links highlighted below for a complete, detailed list of the vector functions.
Additionally, most containers support at least one pair of iterators implemented with nested classes. Iterators enable programs to access the elements stored in a container in a specific order. Provided that the iterator remains in scope, the program can access an element, process it, and return to the container for the next element whenever it is convenient.
Forward Iterators
Reverse Iterators
vector<int>::iterator
vector<int>::reverse_iterator
begin
end
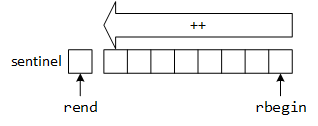
rbegin
rend
for (auto i = v.begin(); i != v.end(); i++)
cout << *i << " ";
for (auto i = v.rbegin(); i != v.rend(); i++)
cout << *i << " ";
0 1 2 3 4
4 3 2 1 0
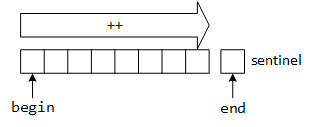
STL iterators.
Iterators allow programs to access container elements in forward and reverse order. The example assumes that v is a vector storing the digits 0, 1, 2, 3, and 4. During iteration, programs access the container data by dereferencing the iterator variable. The auto keyword is a compact and convenient way to define an iterator that serves as the loop control variable; however, programs can replace it with a full iterator specification.
The begin and rbegin iterators initially point to the first and last elements in the structure, respectively. The auto-increment operator moves the iterators relative to the English reading direction: the forward iterator moves from left to right (from the beginning to the end), while the reverse iterator moves from right to left (from the end to the beginning). The loop tests in both examples rely on the != operator, which returns false when the iterator points to the end element. To drive the loop through an additional iteration, iterators create a "dummy" or sentinel object for the loop-test, allowing the loop to process the last or first element (depending on the iterator's direction) before terminating.
C++ Standard Template Library (STL)
Standard Containers Very thorough. See the tables at the bottom of the page.
#include <iostream>
#include <vector>
using namespace std;
double average(vector<int>& v);
int main()
{
vector<int> scores;
while (true)
{
int score;
cout << "Please enter a score: ";
cin >> score;
if (score < 0) break;
scores.push_back(score);
}
cout << "The average is " << average(scores) << endl;
return 0;
}
double average(vector<int>& v)
{
if (v.size() == 0) return 0;
double sum = 0;
//for (int i = 0; i < v.size(); i++)
// sum += v[i];
for (vector<int>::iterator i = v.begin(); i != v.end(); i++)
sum += *i;
return sum / v.size();
}
vector-avg.cpp.
The vector average example revisits the third version of the average program from the Arrays chapter, replacing the large scores array with a vector. Vectors offer three advantages over arrays: First, they don't waste space when storing a few elements while retaining the ability to store many elements. Second, it isn't necessary for programs to test for and avoid buffer overruns. Finally, programs are not responsible for explicitly deallocating vector memory (the destructor does this automatically), as is the case for arrays allocated dynamically on the heap.
#include <iostream>
#include <string>
#include <cctype>
#include <vector>
using namespace std;
void normalize(vector<int>& v, const string& s);
int main()
{
string phrase1 = "To be or not to be: that is the question, "
"whether 'tis nobler in the mind to suffer the slings "
"and arrows of outrageous fortune.";
string phrase2 = "In one of the Bard's best-thought-of tragedies, "
"our insistent hero, Hamlet, queries on two fronts about "
"how life turns rotten.";
vector<int> v1(26);
vector<int> v2(26);
normalize(v1, phrase1);
normalize(v2, phrase2);
for (int i = 0; i < v1.size(); i++)
if (v1[i] != v2[i])
{
cout << "Phrases are NOT an anagram." << endl;
exit(0);
}
cout << "Phrases ARE an anagram." << endl;
return 0;
}
void normalize(vector<int>& v, const string& s)
{
for (char c : s)
if (isalpha(c))
v[tolower(c) - 'a']++;
}
v-anagram.cpp.
The vector-based anagram solution is adapted and simplified from the similar Chapter 8 example. It replaces the arrays storing the character counts with corresponding vector containers. It primarily demonstrates creating a vector with a specific size (highlighted in blue). The figure folds the string literals forming the test phrases across multiple lines to make them easier to display; the preprocessor concatenates them to form two strings.
Determines if two phrases form an anagram by counting the occurrences of the letters in each phrase. Maintains the counts in two vector containers.
Positional access is the hallmark of sequential data structures, which is how programs access array elements regardless of their dimensionality. However, arrays with two or more dimensions are nevertheless stored linearly in memory. Please see Row-Major Ordering.