Unlike pass-by-value, which is a common computer science term, pass-by-pointer is a less-than-official term the text uses to label a special case of pass-by-value. Also known as pass-by-address, this describes the situation in which the argument value passed to a function is the address of a data item, and the function parameter is a pointer variable. (Other programming languages often call this "pass by reference". However, C++ uses that term to name a third passing mechanism described in the next section.) Although the terms are unofficial, experienced C++ programmers understand the implied passing technique. These terms allow us to talk about this passing method more easily and distinguish its syntax and behavior from the other methods.
Pass-by-pointer caveat
The arguments in a pass-by-value function call can be any arbitrary expression, but pass-by-pointer only allows one kind of expression: a memory address. Programmers can formulate the expressions in many ways based on arbitrarily complex arithmetic operations, but they typically rely on only three basic patterns. To help classify the expressions, assume a function named function, a variable named variable, and a structure or class called Person.
Programmers form a simple address-valued expression with the address-of operator and a variable name: function(&variable).
Recall that the new operator allocates memory on the heap and returns its address, allowing programmers to use it as an expression: function(new Person);
Arrays are the exception to the rule stating that pass-by-value is the default C++ passing technique. C++ always passes arrays by pointer. We'll explore this concept in the next chapter.
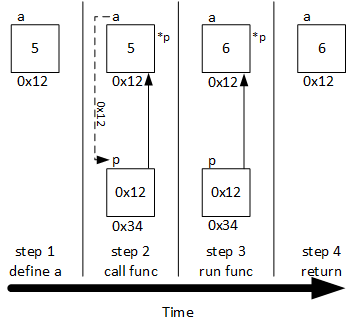
This discussion uses the same technique of articulating C++ statements with a time-varying illustration of memory contents as used in the previous section. Although the changes from pass-by-value to pass-by-pointer are subtle, they are significant, so you must compare the programs carefully. The addresses of variables a (0x12) and b are still arbitrary but play a larger role in this example: the program passes the address of a to the pointer variable p, and while p has an address, its contents are also an address - the address of a.
As in the previous example, simple data are any of the fundamental, built-in data types like char, int, or double. While the example presented below uses an int, the code will exhibit the same behavior with any fundamental data type.
The variable a is defined and initialized with the value 5
The address of variable a is found or calculated with the address-of operator ( & ) function func is called and the address of a (the value 0x12) is passed from the call to the local (pointer) variable p (in essence: int* p = &a;). Notice that while the function is active, *p is an alias for a (they represent the same variable). It is common to illustrate that p points to a with an arrow drawn from p to a
The function does not directly use the contents of p but uses them indirectly, that is, it accesses a indirectly through p using the indirection or dereference operator ( * ). The function increments the value in a (look at that closely - it increments a and NOT p)
The function terminates, p is deallocated, *p. is no longer an alias for a but the value of a is different after the call to func
As before, structured data are typically instances of structures or classes. In addition to reviewing the sections recommended above, it may also be a good idea to review the arrow operator before studying the next example.
struct part
{ char type;
int id;
};
void func(part* p);
int main()
{
part a = { 'd', 10 }; // step 1
func(&a); // step 2
}
void func(part* p)
{
p->id = 1000; // step 3
} // step 4
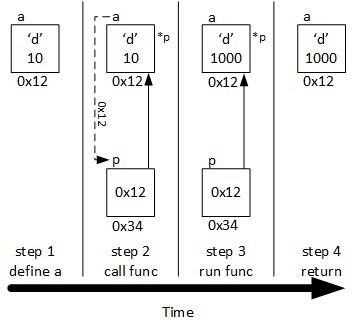
Pass-by-pointer with structured data.
The structure variable a is defined and both fields are initialized
The address of variable a is found or calculated with the address-of operator; the program calls function func and passes the address of a (the value 0x12) from the call to the local (pointer) variable p (in essence: int* p = &a;). Notice that while the function is active, *p is an alias for a (they represent the same structure). Again, it's common to illustrate that p points to a with an arrow drawn from p to a
The function updates the id field of a through p (notice that it is a that is updated, not p). The arrow operator combines the operation of two operators: * and .; it both dereferences p and selects id
The function ends, p is no longer an alias for a, but a is changed after the function call is complete
Pass-By-Pointer: Advantages and Disadvantages
function, pass-by-pointer, pass-by-address, address-of operator, dereference operator, &, *, new
Passing data to a function by pointer is more complex than passing it by value, sometimes making it difficult to characterize the difference as an advantage or disadvantage. When considering the relative merits of the two methods, pass-by-pointer has three notable characteristics. The first is a benefit, the second a drawback, and the third depends on what the problem solution needs.
(Advantage) The execution time required to pass data by pointer is independent of the data's size. The size of a pointer or an address is small and fixed (e.g., the size of a pointer to an int is the same as a pointer to an enormous structure), so pass-by-pointer is fast and efficient even when passing large data items.
(Disadvantage) Pass-by-pointer entails a series of complex, error-prone operations.
Passing the address of a variable demonstrates three error-prone operations:
int u;
...
read(&u); // Get the address of the variable in the function call
...
void read(int* v) // Make the parameter a pointer in the definition and prototype
{
cin >> *v; // Dereference the pointer parameter everywhere it's use in the function
cout << *v << endl;
}
The compiler may not always detect a missed operation, but the program will fail nevertheless!
Managing dynamic memory, allocated with new, is challenging. Neglecting to deallocate heap memory somewhere in the program causes a memory leak.
Pass-by-value allows general expression arguments in function calls, making it more flexible than pass-by-pointer. For example, pass-by-value allows 10, a + b, and sqrt(x) as arguments, but none of these have an address, so the program can't pass them by pointer.
(Depends) The parameter name of data passed by pointer is a function-scope alias for the original data. The changes the function makes to the parameter (i.e., the alias) change the original data. We can view this operation as a benefit, allowing programs to quickly pass one or more data items into and out of a function through the arguments. Conversely, we can view it as a drawback if we expect the function to protect the data, preventing change. In this case, programmers can make the parameters const, preventing the function from changing them.