"A namespace is a declarative region that provides a scope to the identifiers (the names of types, functions, variables, etc) inside it. Namespaces are used to organize code into logical groups and to prevent name collisions that can occur especially when your code base includes multiple libraries" (Microsoft Documentation).
Chapter 1 introduced the standard namespace, std, and illustrated two options for accessing the I/O classes it declares:
namespace notation.
Declaring a named entity inside a namespace gives it an extended, qualified name. For example, programs form the fully qualified names of cout and endl by prepending the namespace name and the scope resolution operator.
The using statement forms a shorthand notation for accessing the features declared in a namespace without using the fully qualified name.
Programs can access the entities declared in a namespace using a fully qualified name consisting of the namespace and entity name joined with the scope resolution operator.
All the example programs presented throughout the text and all the programming assignments you have completed depend on the std namespace. Despite using namespaces, we haven't explored how to create them or why they are helpful. This section addresses those omissions.
The namespace Syntax
namespace, scope resolution operator, name collision, name conflict
To understand how namespaces work and why we need them, we must understand what a "name collision" means. Linguists estimate that there are more than a million words in English, with similar numbers in other languages. So, it seems like we should be able to write a program without running out of identifier names. For example, using English's 26-character alphabet, we can form nearly 457,000 four-character patterns, almost half the number of words in the language. But most of those patterns are meaningless. Furthermore, programmers often name programming elements based on their role in a program (i.e., on what they do). This practice sets the stage for potential name collisions or name conflicts.
It's easy to resolve name collisions by changing one of the colliding names when a programming team works together to create a system. But when we create a system incorporating multi-sourced components delivered as executables and object-code libraries (Figure 4, step 3), it's not possible to change conflicting names. I encountered this problem in a C program integrating a database management system with library code licensed by different vendors. In C++, namespaces solve this problem by creating named scopes.
Vendors avoid name collisions by declaring classes, non-member functions, and global variables in uniquely named namespaces with names typically based on corporate names, which are trademarked and, therefore, unique. Namespaces included in the C++ API are managed and reserved by the ANSI C++ committee. In C++, the scope resolution operator binds the namespace name to the names of its enclosed entities. The name "scope resolution operator" suggests that it helps the compiler determine the scope of otherwise ambiguous programming elements.
int main()
{
Acme::print("Dilbert");
Widgets::print("wing nut");
return 0;
}
// Error - a namespace is an invalid type name
Acme m;
Widgets* w = new Widgets;
(c)
(d)
namespace and the scope resolution operator.
The simplified code introduces the "namespace" keyword and how to create, fill, and use namespace structures. The scope resolution operator (displayed in red) has two operands. The left-hand operand is a namespace name, and the right-hand operand is the name of a feature declared in it. The operator binds the feature to the namespace's scope.
Namespaces are syntactically similar to classes and structures; like them, they create a new, named scope.
The namespace is included with and attached to the function definition with the scope resolution operator. Although not illustrated here, we can include small function bodies in the namespace.
When client code calls a namespace function, it must use the namespace name and the scope resolution operator to form the complete function name.
However, unlike classes and structures, programmers cannot create variables or objects from a namespace.
The figure illustrates a name collision or conflict with non-member functions, but conflicts can also occur with classes and global variables.
Clarifying ambiguous scope with the scope resolution operator.
Programs may contain non-conflicting, overloaded functions (functions with the same name), but proper overloading requires that they have unique parameter lists. In situations like the function chaining example illustrated in (a), it's desirable to have functions with the same name and parameters. These functions are not overloaded, and their names conflict without clarification.
Class beta defines a to_string member function that calls the C++ string class to_string function (see string To Number and Number To string). Without the namespace name and the scope resolution operator, the call becomes a direct recursion function call. Programmers use the scope resolution operator to resolve the ambiguous use of function names, as illustrated here by to_string.
C++ declares the common or standard C++ library functions in the std namespace, and programs can usually access them without ambiguity just by adding the "using" statement at the beginning of a file.
Programming Namespaces
namespace
As the size and complexity of programs increase, programmers need some way to organize and manage namespaces. Namespaces are declarative structures like prototypes and class specifications. They are also containers that wrap and extend the names of functions and classes. Programmers incorporate namespaces in header files to wrap prototypes and class specifications. The following examples demonstrate how programmers add namespaces to function prototypes and class specifications in header files.
#include <iostream>
#include "Acme.h"
using namespace std;
using namespace Acme;
int main()
{
f1();
f2();
return 0;
}
(a)
(b)
(c)
(d)
Putting functions in a namespace.
Together, Acme.h and Acme.cpp form a supplier. Only a modest amount of code is needed to add namespaces to suppliers and clients.
The namespace's body is a block formed by a pair of braces that introduce a new scope. Putting the prototypes in the namespace binds the function name to the namespace. The figure illustrates parameterless functions for simplicity, but parameterized functions are legal and follow the prototyping syntax described previously.
Programmers continue defining functions in source code files that include the namespace header file. The definitions must include the fully qualified names consisting of the namespace and function names.
An alternate syntax opens the namespace to add the function definitions rather than using the fully qualified function names.
A client or application program includes and uses the namespace, allowing it to call the namespace functions. Alternatively, the client can include the namespace but call the functions with their qualified names, Acme::f1(); and Acme::f2();, rather than employing the "using" statement.
In large programs, especially when the supplier forms a separate library, the client and supplier are unlikely to be colocated in the same directory. In that case, the programmers modify the #include "Acme.h" directive in the client to include the supplier's path. For example, #include "dir1/dir2/Acme.h" or #include "/acme/Acme.h". Notice that the forward slash character is the path separator, even on Windows platforms. The text revisits and extends pathnames in chapter 14, File System Organization.
Acme.h
foo.h
bar.h
client
namespace Acme
{
class foo;
class bar;
};
#include "Acme.h"
/*namespace Acme
{
class foo
{
public:
void f3();
};
};*/
class Acme::foo
{
public:
void f3();
};
#include "Acme.h"
/*namespace Acme
{
class bar
{
public:
void f3();
};
};*/
class Acme::bar
{
public:
void f3();
};
#include "Acme.h"
#include "foo.h"
#include "bar.h"
using namespace Acme;
int main()
{
foo f;
bar b;
f.f3();
b.f3();
return 0;
}
Putting classes in a namespace.
Programs can open and close namespaces without limit. Each time a program opens them, it adds new declarations without removing or affecting those already in the namespace. This process allows programs and libraries to build large namespaces from smaller, more manageable files.
Declaring a class inside a namespace binds the class to the namespace. As illustrated in this example, the keyword class creates a forward declaration for classes foo and bar.
This organization allows programmers to continue specifying each class in a separate header file while still putting them in the same namespace. Programmers can specify the full class name in the namespace (as in the commented-out example) or use the fully qualified class name to specify the class. Programmers still put the member function definitions in separate source code files, but reference them with fully qualified names.
Clients must #include the class header files (foo.h and bar.h), but including the namespace header (Acme.h) is optional because the class headers include it. This example demonstrates the using statement, but programmers may omit it and use the fully qualified class names: Acme::foo and Acme::bar instead.
Programmers continue putting the member function definitions in appropriately named source code files, choosing between two namespace notations.
The Pros And Cons Of The using Statement
namespace, using
Figure 1 illustrates two options for accessing namespace entities. The programming examples appearing throughout the textbook illustrate my preference for option (a), but this choice is not universal. Odumosu Matthew outlines three objections to the using namespace std; option, and extends those argument to the using statement generally.
Namespace Pollution: The using namespace statement increases the risk of naming conflicts caused by two or more namespaces declaring the same identifier.
Readability: The using namespace statement obscures the source of an entity name, making it more difficult to understand.
Maintenance: Resolving a name conflict introduced by naming a newly added entity the same as an existing entity in a used namespace requires refactoring (redesigning, restructuring, and rewriting) code.
He recommends, as a better practice, explicitly naming the namespace, as in Figure 1(b), when using an entity, suggesting that the practice will reduce these problems. His objections are worthy of consideration.
Namespace Pollution
namespace pollution (definition), name collision (definition), name conflict (definition)
Namespace pollution occurs when the same identifier (name) describes numerous programming elements such as classes, functions, or variables. Name collisions or name conflicts occur when the compiler is unable to determine which element an identifier refers to during compilation. The section opens with a definition suggesting that namespaces declare "the names of types, functions, variables, etc." In terms of C++ features, namespaces declare classes, non-member functions, global variables, and typedef statements. Figure 2 illustrates namespaces with non-member functions, so the text describes the following examples with classes without loss of generality. I argue that two architectural organizations and one fallback method can realize the same benefits while avoiding excessive coding notations.
Architecture 1: One Class Per Header File
using
The primary way C++ programmers limit class name conflicts is by specifying each class in a separate header file, as demonstrated by the Time and fraction classes. This organization affords programmers considerable namespace control using a familiar mechanism: the #include preprocessor directive. A simple example demonstrates how the directive helps reduce name conflicts.
#include <iostream>
//#include <iomanip> // (i)
#include "setw.h" // (ii)
using namespace std;
int main()
{
cout << setw(20) << "Hello World\n"; // (iii)
return 0;
}
Name declaration vs. class specification.
Namespaces and header files have related but distinct purposes.
Although the namesetw is declared in the std namespace, its specification is located in the <iomanip> header file.
The example program uses the standard namespace. However, if it doesn't #include <iomanip>, it can't "see" the setw specification, and fails to compile.
Alternatively, programmers can create their own setw manipulator, placing it in an appropriately named header file.
The setw manipulator the program uses depends on the included header file.
A non-standard setw manipulator that does not conflict with the version in the standard namespace. Chapter 11 discusses how to create new versions of operators, such as <<. However, focusing on the class name is sufficient to understand the example.
Although two functions have the same name, setw, the program controls which function it uses with the #include directive, avoiding a name collision.
Architecture 2: Components And Anonymous Namespaces
component (definition), interface, namespace pollution, compilation unit (definition), translation unit (definition), linkage, external linkage (definition), internal linkage (definition)
Large, complex C++ programs consist of numerous classes, objects, and non-member functions, often developed by independent teams. Organizing these various parts into relatively independent components that reflect a common purpose makes programs easier to understand and manage. Teams can focus on different components based on their respective expertise, while application programmers access their services and incorporate them into client programs through narrowly defined interfaces.
Component1
"A modular part of a system that hides its implementation behind a set of external interfaces" (p. 119).
"Good components define crisp abstractions with well-defined interfaces, making it possible to easily replace older components with newer, compatible ones" (p. 193).
Interface1
"A set of operations that specify a service of a class or component" (p. 157).
When programmed, a component is a self-contained unit of related functions and objects that cooperate to provide a significant software service. Components communicate or interact with external program code through interfaces implemented as functions.
Human interaction: Called the user interface today, and implemented as a GUI, a CLI, or a batch file (e.g., a shell script).
Problem domain: The application using the other components and dedicated to solving a specific problem, often called the the client.
Task management: Complex programs often utilize concurrent or parallel programming requiring coordination that requires synchronization and control.
Data management: Complex programs often use large amounts of data stored in a database or organized in extensive data structures in memory.
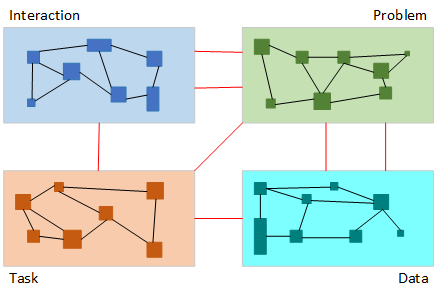
Abstract components.
The Coad & Yourdon2 design technique utilized four named components (p. 26). Although obsolete and largely supplanted by the UML, which doesn't limit or name components, the Coad & Yourdon components help illustrate how components organize large programs and reduce name collisions. The figure abstractly illustrates components as large boxes, and their parts, classes, objects, and functions, as smaller boxes nested in their respective components. Although not illustrated, components are recursive, meaning that the parts can also be components, but nesting beyond three or four levels becomes confusing.
Components are highly cohesive structures with boundaries that encourage implementation by different teams, who name components to reflect their distinct responsibilities. The parts share and distribute the responsibilities of their components. So, following good programming style, developers name each part so that the names reflect the part's component membership and contribution. Consequently, the part names in a component might be similar but distinct to reflect their varying contributions. This naming protocol eliminates or deduces name conflicts.
The figure illustrates the many intra-component connections as black lines. It represents the relatively fewer inter-component connections as red lines, joining components at their interfaces. It is the red, inter-component connections that are most prone to name conflicts, occurring when two or more components have interface functions with the same name. Following the illustrated design, the conflict-prone inter-component connections are relatively few.
The previous figure describes how components reduce or eliminate name conflicts while still exploiting the using keyword. However, to be useful in authentic programs, developers must replace the abstract descriptions with concrete implementations. Defining three terms helps transition from an abstract representation to a concrete implementation.
Compilation or translation unit
The smallest group of instructions a compiler can process or translate, corresponding to a source-code file and its included header files.
External linkage
External linkage allows the linker or loader to join functions and variables (including objects) defined in one compilation unit with another unit.
Internal linkage
Internal linkage prevents the linker/loader from joining functions and variables (including objects) defined in a compilation unit with any other unit, restricting access to them to a single file.
C++ allows developers to nest namespaces - to put one inside another - but the accepted programming style recommends nesting them no more than three or four levels deep. Furthermore, it also allows developers to create anonymous namespaces, namespaces without names. Type specifiers (including classes), functions, and variables defined in an anonymous namespace have internal linkage, "hiding" them from other files or compilation units. C++ developers implement components as files with nested named and anonymous namespaces. The following figure illustrates component implementation with two abbreviated Coad & Yourdon components.
Implementing components with anonymous namespaces.
The figure illustrates one way to implement components with files and namespaces. It also demonstrates how names can reduce name conflicts or collisions. Public and non-member functions within either namespace form the intra-component connections, but only the functions in the outer namespace serve as inter-component connections.
The nested anonymous namespace contains type specifiers (classes in this example) and component data. Everything in the anonymous namespace is hidden from the rest of the program, making it impossible for its names to collide or interfere with others in the program. Functions and data (including objects) in the named outer namespace are exposed and available to the program.
Programmers must exercise caution when putting namespaces in header files. Named components can only be defined once, but may be declared any number of times. Putting a namespace in a header file causes no problems as long as it only contains declarations - function prototypes in this example.
Programs utilize components by including the appropriate header file and accessing the component interfaces with the namespace and scope resolution operator, or the using statement. Carefully named interface functions reduce name conflicts.
Fallback: Resolving Name Conflicts
resolving name conflicts, name conflict, name collision, using
In a program rigorously implemented with the object-oriented paradigm, classes and components usually provide sufficiently distinct scopes for most functions and data, thereby reducing the likelihood of name collisions or conflicts in a program. However, they cannot guarantee elimination. If a name conflict occurs in a program, programmers can always fall back to using the fully qualified name consisting of the namespace and the entity names.
namespace Acme
{
class foo;
class dlilbert;
};
namespace Widgets
{
class foo;
class wally;
};
#import "/Acme/foo.h"
#import "/Widgets/foo.h"
using namespace Acme;
using namespace Widgets;
int main()
{
Acme::foo f1;
Widgets::foo f2;
dilbert d;
wally w;
return 0;
}
Disambiguating name conflicts.
Name conflicts generally arise when a client program combines library or supplier code from multiple vendors. Each vendor names their functions or classes without regard for the names used in other libraries.
This example illustrates two namespaces, each originating with a different vendor. Both namespaces declare a class named foo.
Programs using both namespaces will experience a collision, but client programmers can clarify or disambiguate the conflict with fully qualified class names as Matthew recommends.
Given its general nature, it's easy to imagine numerous classes having a display function. In the previous figure, two classes, each in a different component, defined display functions. The Data component didn't include it in its interface, and the Interaction interface wrapped it with a more restrictive name. This example modifies both components, exposing their display functions.
The client program utilizes the fully qualified component (namespace) names to disambiguate the display function calls.
Rather than use fully qualified class names throughout a program, I prefer to use them when necessary and rely on the more compact notation otherwise. The using statement still allows access to non-conflicting names in both examples.
Readability And Maintenance
components, using
Where name conflicts are unequivocally programming errors - they prevent the program from compiling - readability is more subjective. The subjectivity doesn't diminish the importance of readability, but it does make assessing different approaches more challenging: code one programmer finds readable, another may not. std::cout undeniably conveys more information to a reader than cout, but the significance of the additional information is arguable. Programmers with a moderate level of experience know that cout is specified in the std namespace. Classes specified in specialized namespaces appear infrequently in programs and are limited to specific packages. In the case of specialized namespaces, a suitable comment will clarify any ambiguities, while still allowing the program to use a compact notation.
The lifespans of software systems vary significantly, with some systems operating for decades. The longer a system persists, the more likely it is to need maintenance: extension, adaptation, and correction. While readable code is essential for maintainable software systems, maintainability entails more than choosing how programmers access entities specified in a namespace. Maintainability rests on robust, well-designed data structures that isolate and control access to the stored data. It further requires tight, cohesive functional units with minimal inter-unit connections that limit and localize the effects of internal changes. The architectural organizations described above implement these characteristics, enhancing maintainability far more than explicitly naming the namespace specifying an entity.
using Statement Conclusions
using
Programmers working for an institution that has programming standards should follow those standards. Students submitting programs for scoring or evaluation should follow the instructor's requirements. In the absence of explicit standards or requirements, or when programmers create their own products, they adopt and follow their personal style. Whether they favor or disfavor the using statement is a matter of taste.
Booch, G., Rumbaugh, J., & Jacobson, I. (2005). The unified modeling language (2nd ed.). Addison-Wesley.
Coad, P. & Yourdon, E. (1991). Object-oriented design. Yourdon Press.