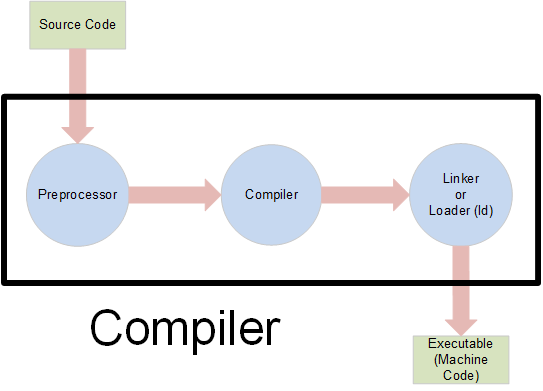
The process of translating C++ source code into an executable program is called "compiling the program" or just "compiling." We usually view the compilation process as a single action and refer to it as such. Nevertheless, a modern C++ compiler consists of at least three separate programs:
The C++ compiler system. The compiler consists of three separate programs or stages:
The preprocessor. The first program in the compiler system reads and processes the source code file, creating a temporary file of the processed code. This stage processes directives beginning with the # character and copies other C++ statements from the source code to the temporary file.
The code translator is often called "the compiler." To avoid confusion, we'll call the middle program the compiler component. This program reads and then deletes the temporary file the preprocessor creates. It translates the source code to object code (machine code plus descriptive information for the linker or loader), which it saves in an object code file. Depending on the operating system, object code files end with either .o or .obj.
The linker (also called a loader on some operating systems) reads and links together the object code files, producing the final executable program.
Most of the time, we collectively refer to all three programs as "the compiler." Whenever we say "the compiler," context is usually sufficient to clarify if we are talking specifically about the middle component or all three components together. If the context is not enough, then we must explicitly clarify our meaning to avoid any confusion.
Modern integrated development environments (IDEs) such as Visual Studio bundle the preprocessor, compiler, and linker to work as a single unit and operate through a common interface. Programmers initiate the compilation process with a single command (typically a single button press or menu item). Modern IDEs also include many additional tools:
a graphical user interface,
a text editor for writing and editing source code,
a dynamic syntax checker that detects syntax errors while you write code,
a debugger to help locate logical and runtime errors,
and a profiler to measure how much time the program spends in each function.
Although programmers control these features through a common interface, most are implemented as separate programs.
The Preprocessor
The preprocessor handles statements or lines of code that begin with the "#" character, which are called "preprocessor directives" or just "directives" for short. Note that directives are not C++ statements (and therefore do not end with a semicolon) but rather instruct the preprocessor to carry out some action. The preprocessor reads and processes each file one at a time from top to bottom. It does not change the contents of the files it processes but creates a temporary file containing the processed code. The compiler component reads and translates the temporary file from C++ to machine code. When the compiler component finishes processing the code in the temporary file, it removes the file. Two of the most common directives, and the first that we will use, are #include and #define.
The #include Directive
The #include directive consists of two parts, all on the same line and separated by at least one space:
#include
the name of a file (usually a header file)
Compilers often provide frequently needed program operations with functions stored in a library of reusable functions. Header files contain information describing the library functions, allowing the compiler component to verify that the program correctly calls or uses them. When the preprocessor encounters the #include directive, it opens the header file and copies the contents into the temporary file. The symbols surrounding the name of the header file are important and determine where the preprocessor looks for the file.
<name>
The angle brackets denote a system header file describing the compiler's library functions and directing the preprocessor to search for the file wherever the system header files are located (which varies from one compiler to another and from one operating system to another).
"name.h"
The double quotation marks identify a header file written as a part of a program. The quotation marks instruct the preprocessor to look for the header file in the current directory (i.e., in the same directory as the C++ source code). Header files a programmer writes as part of an application program typically end with a .h extension.
You might see two kinds of system header files in a C++ program. Older system header files end with a ".h" extension: <name.h>. These header files were created for C programs but are usable with C++. Newer system header files do not end with an extension <name> and are only usable in C++ programs.
#include <iostream>
#include "person.h"
Alpha.h
#include "Beta.h"
...
Beta.h
#include "Gamma.h"
...
Gamma.h
stuff
...
(a)
(b)
(c)
(d)
Example #include directives. The #include directive causes the preprocessor to open and read the named file. It completes any #define operations (detailed in the following section) while copying the processed contents of the input file to the temporary file. The ellipses represent detail omitted for simplicity.
File names appearing between < and > refer to system header files; file name appearing between an opening and closing " refer to header files written by the programmer as a part of the program.
One header file may include others, making arbitrarily long inclusion chains. When the preprocessor encounters the #include "Beta.h" directive, it opens and processes Beta.h. When it finishes processing Beta.h, it returns to Alpha.h and processes the code represented by the ellipses.
Similarly, the preprocessor opens and processes Gamma.h when it encounters the #include "Gamma.h" directive. When finished with Gamma.h, it returns to Beta.h and processes the code represented by the ellipses.
Practically, the inclusion chain must end and allow the preprocessor to finish.
Note
The include directive does not end with a semicolon, and there must be at least one space between the directive and the file name.
The #define Directive and Symbolic Constants
The #define directive introduces a programming construct called a macro. A simple macro only replaces one string of characters with another string. We'll look at more complex, parameterized macros in Chapter 6. The #define directive is one (old) way of creating a symbolic constant (also known as a named or manifest constant). The const and enum keywords are newer techniques for creating constants and are presented in more detail later. It is a well-accepted naming practice to write the names of symbolic constants with all upper-case characters (this provides a visual clue that the name represents a constant).
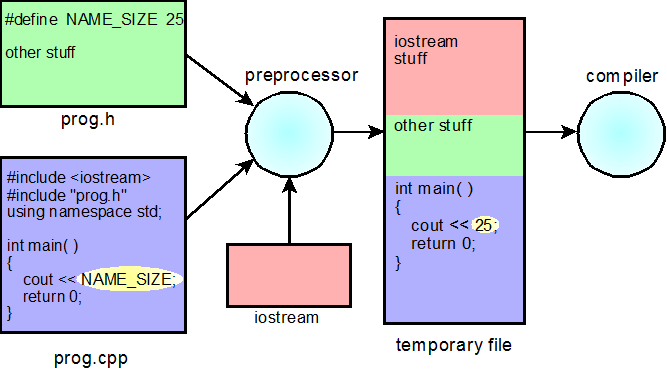
The preprocessor: #define and #include. The preprocessor handles directives that begin with the # character and creates a temporary file to store its output. The middle "bubble," the compiler component, reads the temporary file and continues the compilation process. The figure illustrates how the preprocessor expands the macro #define NAME_SIZE 25:
A programmer writes "NAME_SIZE" in the C++ source code
The preprocessor replaces the characters NAME_SIZE with the characters 25
The compiler component "sees" and compiles "25" rather than NAME_SIZE
Symbolic/named/manifest constants are helpful in two significant ways:
They help make the code more self-documenting. NAME_SIZE, viewed in the context of a specific program and the problem that it solves, likely conveys more meaning to a reader than does "25."
They help make it easier to change specific values as a program evolves. Imagine that a program uses the number 25 in more than one way. In some places, it's the maximum size of a name, but elsewhere, it is the maximum number of students in a class. If we need to change the 25 that denotes the size of a name, we can't use a global search-and-replace operation as it will change all occurrences of 25, including those places where it is the number of students. This problem is even more aggravating if the program spans many files. Using a symbolic constant reduces the amount of work needed to update the program by allowing the programmer to make the necessary change in only one place, the "#define" directive.
Note
The #define directive does not end with a semicolon, and there must be at least one space between the directive and the identifier (i.e., name) and between the identifier and the defined value; the defined value (the third part of the directive) is optional.
The Compiler Component
The compiler component, the middle program in the overall compiler system, is the system's most extensive and arguably the most critical part. The compiler translates C++ source code into the machine code that a specific computer "understands" and can execute. The picture below suggests that a single program can consist of multiple source code files. Programs come in a vast range of sizes, from tens of lines of code to millions of lines. It is both awkward and inconvenient to deal with large programs in a single source code file, and spreading them over multiple files has many advantages:
It breaks large, complex programs into smaller, independent conceptual units that are easier to understand and easier to follow
It allows multiple programmers to work on a single program at the same time; each programmer works on a separate set of files
It speeds up compilation. The compiler component stores the generated machine code in an object file, one object file for each source code file. The compiler system does not delete the object files, so if the source code file is unchanged, the linker uses the existing object code file.
It permits related programs to share files. For example, office suites often include a word processor, a slide show editor, and a spreadsheet. By maintaining the user interface code in one shared file, they can present a consistent user interface.
Although less important, it allows developers to market software as object code organized as libraries, useful when supplying code that interfaces with applications like a database management system.
The preprocessor processes each source code file one at a time and produces a single temporary file. Similarly, the compiler processes each temporary file one at a time and produces one object file for each temporary file. Object files contain machine code and information the linker uses to match programming elements (like functions) spanning the files. (Note that "object" in this context has nothing to do with the objects involved in object-oriented programming.)
The compiler component also detects syntax errors and provides the diagnostic output programmers use to find and correct those errors. Despite all that the compiler does, its operation is transparent to programmers for the most part.
The Linker Or Loader
The linker is the third and last component of the full compiler system. It takes the object files created by the compiler and links them together, along with library code and a runtime file, to form a complete, executable program. The name of the executable file depends on the hosting operating system: On a Windows computer, the linker produces a file whose name ends with a ".exe" extension. On Linux, Unix, and macOS systems, the linker produces a file named a.out by default. Users may also specify a name that overrides the default (note that executable files do not have a standard extension on these systems).
Compiler Operation Summary
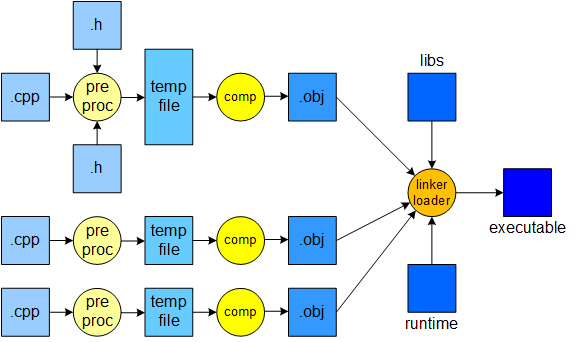
The complete C++ compilation process. Programmers write large, complex C++ programs in multiple files - including source code (.cpp) and header (.h) files. The first two compiler components process the source code files independently (i.e., one at a time). The linker (or loader) is the only component that processes the program as a complete entity.
The preprocessor performs textual substitutions specified by #define directives and copies the contents of files named with #include directives, storing the results in a temporary file.
The compiler component translates the contents of the preprocessed source code files into machine code and stores the machine code in object files. Object file names end with a ".obj" extension on Windows systems and a ".o" extension on Linux and macOS systems. Object files consist mainly of machine code but have a dictionary listing the functions and variables defined in the file. The linker/loader uses the dictionary to join the object files.
The linker/loader combines or links all the object files, any needed library code, and a small runtime file to form an executable program. Executable file names end with a ".exe" extension on Windows computers; other operating systems follow different naming conventions.