Two operations in the previous version of the direct access Rolodex program conflict. Assuming a large, authentic database file, inserting records randomly is difficult and prohibitively time-consuming. Although programs can sort or reorganize small files (as was done in the b-rolodex example), sorting long files of large records is infeasible. Consequently, authentic database programs append new records at the file's end, leaving a linear search as the only way to locate a given record. However, a linear search through a large file is also a prohibitively lengthy process. Programmers resolve this conflict with the Indexed Sequential Access Method (ISAM), the final access method the text covers.
ISAM allows programs to access specific records in large data files directly. In addition to the data file, the method also requires at least one index file. Index files are also called key files, so the access method is also known as the Keyed Sequential Access Method (KSAM). Programmers implement an ISAM system using the block I/O and direct access functions described previously. Familiarity with the roles that each file plays in an ISAM system makes it easier to understand and discuss.
Data File
Index Files
consists of fixed-length records (instances of structures or classes)
each data record consists of many different fields
the file is very large:
each data record is large
the file contains many records
the file is too large to fit in memory, making it impractical to reorganize
new data records are appended at the end of the data file
consist of records with two fields
a key duplicating one data record field
the record number of a data record with a field matching the key
index files may support a fast-search algorithm (e.g., B-trees, hashing, etc.)
each index file allows searching the data file on one data record field
implement an associative search
ISAM file roles and operation.
An ISAM system allows programs to locate a specific data record quickly or access them sequentially in index file order. While it's convenient to think in terms of record numbers - and the text describes the ISAM method that way - programmers can choose to store either record numbers or absolute addresses in index files.
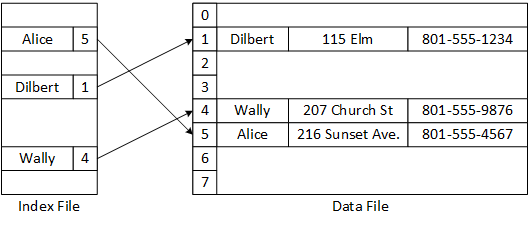
Data records often contain many fields, and programs may use any field as a key for an associative search. Each designated key field requires a dedicated index file, binding a key to a record number, and facilitating searching for specific data records in large data files. The following figure illustrates the relationship between the data and index files and outlines the ISAM operations.
ISAM files and operations.
This example continues storing Rolodex cards as records in the data file but adds an index file, forming a simple ISAM system. The index file stores and organizes records, treating contact names as keys. If the index records are small enough to sort easily, they define a fast mapping between the keys and data records. To focus on the ISAM operations, the example makes a few simplifying assumptions:
key names a class with two fields: a name, the key, and a record number.
index is an fstream object associated with a file storing key objects or records.
c is a card record.
The key constructor builds a key record, k, with a name and data record number.
R is the record number of a data file record.
Add A Data Record
Move to the end of the data file: data.seekp(0, ios::end);
Save the position: pos = data.tellp();
Write the data record: data.write((char *) &c, sizeof(chunk));
Create an index record: key k(name, pos);
Move to the end of index file: index.seekp(0, ios::end);
Write the index record: index.write((char *) &i, sizeof(key));
Search For A Data Record
Search the index file for the contact's name. This step assumes there is a method for quickly searching through the relatively small index records.
If the search finds the key, get the record number, R, saved with it.
Move to the data record corresponding to R: data.seekg(R * sizeof(card));
Read the data record: data.read((char *) c, sizeof(card));
Conceptually, the program finds "Alice" in the index file and gets the position 5. It moves the read pointer in the data file to position 5 and reads the complete Alice record.