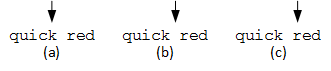The Unix and Linux operating systems provide a utility named wc (short for word count) that counts the words, lines, and characters in a list of files. The utility prints the counts for each file and the totals for all files in the list. We'll write a simplified version of the wc utility to demonstrate a more complex switch statement. However, this program is uninteresting and difficult to test if it takes input only from the console. So, we'll jump ahead and see how to read input from a file. Like the original wc program, our version will also count words, lines, and characters. Unlike the original, our version will read data from only one file and will lack the command line options or switches altering the counts.
wc Test Case
Our first task is to create a test case - simple data that we can use to verify that the program produces the correct counts. Creating a test case or even thinking about testing a program before writing it may seem odd. However, in organizations with separate development and quality assurance teams, it's common for the teams to work in parallel and cooperate. Focusing on the test case data helps guide us through the steps to solve the problem. The representation and the associated algorithmic steps developed from it will bridge the problem and the programmed solution.
See the\n
quick red\n
fox
3 lines
5 words
17 alphabetic characters
2 space or blank characters
2 new-line characters
Test Case
Word count program test case. Our test case consists of just five words spread over three lines. We can easily count the characters (letters A-Z, a-z, digits 0-9, and punctuation marks). But the spaces and tabs between the words and the new-line characters separating each line are also characters. (The \n appearing in the test data is an escape sequence representing a single new-line character.) So, totaled, there are 21 characters in the test case.
Solving The wc Problem
Typically, writing a program to solve a problem requires solving many sub-problems before programming can begin. Even after we simplify the program, it has five sub-problems that we must solve. The first sub-problem is defining what we mean by a "word." We must develop algorithms for the next three sub-problems: counting characters, lines, and words. The last sub-problem, reading data from a file, is a special case because we do not formally learn how to do this until much later in the textbook.
What is a word?
For this demonstration, we'll define a word simply as a sequence of characters separated by white space, where white space is a space, a tab, or a new line. This definition implies that we should treat digits and punctuation marks like the alphabetic characters A-Z and a-z. How we count words will depend on this definition. For example, hello*@ 12#$ is counted as two words. The program will use an accumulator, words, to count the number of words in a file.
Counting characters
The program will also need an accumulator, chars, to keep a count of the number of characters in the input file. The program will read data from the file one character at a time, which makes counting the characters very easy: read a character and increment the count by one.
Counting lines
The program will need another accumulator, lines, to count the number of lines in the input file. Although it is possible to read text one line at a time, which makes counting lines very easy, doing so makes it more difficult to count words and characters. A single new-line character separates Each line from its neighbors in a text file. It's easy to count the new-line characters, but there are two important considerations:
First, most people would say that the test case illustrated in Figure 1 contains three lines, but the data only contains two new-line characters. Now, we face an inconsistency over which we have no control. Some systems treat the new-line line character as a line terminator and require a new line at the end of every line; other systems treat the new-line character as a line separator, which is optional at the end of the last line. For this example, we'll create the test case with the Visual Studio editor on a Windows system, so we'll treat the new-line character as a line separator as it appears in Figure 1. We'll also compensate for the difference between the apparent number of lines and the number of new-line characters by taking the rare step of initializing the accumulator variable to 1 rather than to 0.
The second consideration is that the new-line character serves two purposes. It is both a white-space character that separates words and a line separator. Interpreting the new-line character in both ways is the primary feature of the switch statement demonstration.
Counting words
Finally, counting the words in a file requires one more accumulator, words, and introduces a new problem that requires a new kind of variable. Words have at least one character, but they may be arbitrarily long. So, as the program reads each character in a word, it must be careful not to count the word more than once. The program will use a flag, in_word, to "remember" if it is currently in a word (i.e., reading characters that are part of a word) or not. There are only two possibilities: either the program will be in a word or not. So, we can make the flag a variable of type bool. The program uses all white-space characters as word separators, so we set the flag to false whenever any of the white-space characters are detected and set it to true whenever a non-white-space character is input. We will only count words when the program reads the first character of the word from the file.
Counting words separated by white-space characters.
The program is in the "In Word" state when it reads the character 'k,' so it counts 'k' as a character, but it doesn't count "quick" as a word
When the program reads the space character, it is still in the "In Word" state, but the space character separates words (i.e., it ends one word, and any subsequent non-white-space characters must belong to a new word). So, we count the white-space character as a character, but we don't change the word count. Furthermore, the program changes to the "Not In Word" state
The program is now in the "Not In Word" state, so when it reads the character 'r,' which it counts as a character, it also counts "red" as a word and changes back to the "In Word" state
In this way, the program counts every character, but it only counts words when it reads the first character of the word.
Reading from a file
Previous programming demonstrations have used cin and cout to read input from and write output to the console. The console is just a file (or, more accurately, many files: one for input and several for output). cin and cout are objects instantiated from two stream classes: istream and ostream, which are declared in <iostream>. Instances of ifstream (short for input file stream) behave very much like instances of istream but can also read from disk files:
<fstream> is a header file that declares the classes needed for creating the objects that can read and write files.
One of the ifstream class's constructors takes the name of a file as an argument and opens the file for reading.
get is a stream member function that reads one character from an input stream and returns it as an integer.
EOF (short for end of file) is a symbolic constant that represents a special value signaling that the program has read all data from a file (i.e., the read operation reaches the end of the file).
#include <iostream> // for console I/O
#include <fstream> // for ifstream
#include <iomanip> // for setw
using namespace std;
int main()
{
ifstream file("fox.txt"); // (a)
int chars = 0; // (b)
int lines = 1;
int words = 0;
bool in_word = false;
int c;
while ((c = file.get()) != EOF) // (c) & (d)
{
chars++; // (e)
switch (c) // (f)
{
case '\n': // (g)
lines++;
// fall through
case ' ': // (h)
case '\t':
in_word = false;
break;
default: // (i)
if (! in_word) // (j)
{
in_word = true;
words++;
}
break;
}
}
cout << setw(8) << lines <<
setw(8) << words <<
setw(8) << chars << endl;
return 0;
}
wc.cpp. The word count program counts a file's lines, words, and characters. Recall that the cases are examined from top to bottom, that execution begins with the first case that matches the expression in the switch, and that once execution begins, it continues until processing a break or reaching the end of the switch statement.
Defines an input file stream object named file that can read the contents of a file named "fox.txt"
The accumulators, the flag, and an input variable
The "get" function gets or reads one character from the file and stores it in the variable c (the highlighted code)
The loop runs as long as the last character read in is not the end-of-file indicator (the symbolic constant EOF), i.e., as long as there is unread data in the input file
Increment the character count
Test the value stored in variable c
If the character just read is a new line, increment the line counter, but execution continues into the next two cases because the case does not end with a break. Forgetting a break is a common programming error, so we add a comment stating that the absence of a break is a deliberate part of the program. In this way, the new-line character acts as both a line separator and a word separator (i.e., as white-space)
Reading any of the three white-space characters signals that the program is between words - that is, it's not in a word - and the flag is set to false
The default case corresponds to c != WS and processes all non-white-space characters.
If the program is not in a word - that is, the last character read was white-space - then the character must be the first character of a new word, so set the flag to true and count the word
Positioning The wc Data File
Our next step is to create the file containing our test case. Contemporary operating systems (e.g., Windows, macOS, Unix, and Linux) use a tree-structured file system. Whenever a program runs, it does so in an environment provided by the host operating system. An essential part of that environment is a location in the file system - a directory or folder - called the current working directory or CWD. Based on how we have written the program, it can only open and read the test file if it is in the correct place in the file system - the CWD.
(a)
(b)
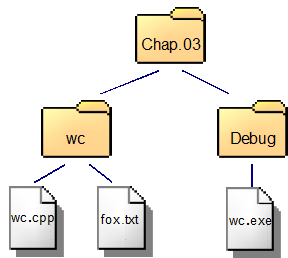
Files in a Visual Studio project.
How we run the word count program affects which directory the operating system assigns as its current working directory and, therefore, where we place the test case file. The "Chap.03" directory corresponds to the VS solution and "wc" to the project.
If we run the program through Visual Studio, the CWD is the project folder (i.e., the folder containing the .cpp file).
If we run the program from the command line, the CWD is the same directory in which the executable program file (i.e., the .exe file on a Windows computer) is located. Although the overall file structure may differ on computers running a different operating system, the CWD is still the same directory where the executable is located.
Other IDEs may have different conventions than the ones described above. Furthermore, different text editors may also embed slightly different characters (beyond those of the test case) in the file, which will alter the results from what we expect. For example, the vi text editor and its derivatives always place an extra new-line character at the end of the entered text. We'll use Visual Studio to create the test file and run the program, ensuring that the test file is located correctly and does not place any unexpected characters in the text data.
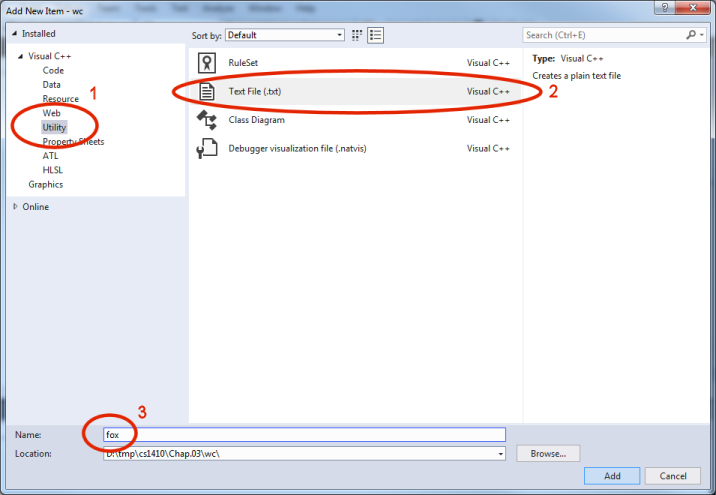
Adding a text file to a project. Adding a text file containing the test case begins with the familiar "Add New Item" dialog: In the "Solution Explorer," right-click the project name, select "Add" from the fly-out menu, and then select "New Item" from the next menu. However, the steps taken in the dialog differ from those needed to add a source code file.
Select the "Utility" option in the upper left panel.
Select "Text File" in the main panel. Unfortunately, the location of this option varies from one version of Studio to another. If the menu doesn't show the text file type, return to step 1 and look under other options
Enter the name "fox" and then press the "Add" button
Testing The wc Program
Proceed to enter the test case data as it appears in Figure 1 into the newly created file. Be very careful as you enter the new-line characters: The \n escape sequence in Figure 1 makes the single new-line characters visible to us while we design the test case; in place of \n, press the ENTER key. Also, note that the last line does not end with a new line; leave the cursor following the last "x" and save the file. Now that the test case file is filled and positioned correctly, you may compile and run the program as you normally would.
3 5 21
See the\n
quick red\n
fox
(a)
(b)
Output from the wc program. The program output can vary from one operating system to another. The output illustrated here corresponds to running the program on a Windows computer.
The wc program counts 3 lines, 5 words, and 21 characters, the expected counts.
The test case includes the "invisible" characters new-line characters at the end of the first two lines.