Computer programs seem capable of representing an infinite variety of "things," from the windows and buttons in a graphical user interface (GUI) to the visually stunning locations in a game to the emerging atmospheric patterns used to predict tomorrow's weather. More incredible than the limitless number of things a computer program can represent is that the program creates all of these things from just a few kinds of simple numbers! This section presents the fundamental, built-in, or primitive data types that C++ programs use.
Data Types
Whenever a C++ program uses data, the data must be typed. Typing data allows the computer to do two things. First, different types or kinds of data use different amounts of memory, and the data type tells the compiler how much memory to reserve or allocate to hold the data. For example, an int uses 4 or 8 bytes of memory, while a double uses 8 or 16 bytes of memory. All data stored in memory is just a sequence of binary digits, 1s and 0s, and has no meaning until the code accessing it gives it meaning. So, the second thing that the data type tells the computer is how to interpret the binary digits. For example, the bit-pattern representing an int 2 is quite different from the bit-pattern representing a double 2.
A few factors affect the size of some data. The most significant factor is the hardware. The American National Standards Institute (ANSI) controls the specification of the C++ programming language. For the best performance, the ANSI C++ standard specifies that an int shall be the same size as the native hardware word size. A word size of 32 bits was common for years, but 64 bits is the current standard. The second factor is the compiler, which, on a 64-bit computer, can create 32- or 64-bit programs. The following table lists the most commonly supported data types, their typical sizes, and the range of values they can store.
C++ is an extensible language, meaning that programmers can create and use new data types in a program. Programmers create new data types with structures, classes, and enumerations, all covered in later chapters. The data types recognized and processed directly by the compiler are called fundamental, built-in, or primitive data types. Programmers don't create the fundamental data types - they are an intrinsic part of the C++ language.
Type
Size (bytes)
Value Range
Comments
void
0
N/A
Used as a function return type and typeless pointers (treated much later).
bool
1
false or true
In C/C++, zero is false, and non-zero is true.
integers
char
1
Typically -128 to 127, but 0 to 255 on some hardware
2-byte wide characters, called wchar, are also supported.
short
2
-32,768 to 32,767
Formally short int
int
varies 4 is typical
-2,147,483,648 to 2,147,483,647
The size and range are implementation-dependent, but 8 bytes is now typical.
The C++ specification only requires that short ≤ int ≤ long.
long
4
-2,147,483,648 to 2,147,483,647
Formally long int
float
4
±3.4028234 × 10±38
6 - 7 significant digits
floating point
double
8
±1.79769313486231570 × 10±308
~15 significant digits
C++ fundamental, built-in, primitive data types. Types highlighted in goldenrod represent integers of different sizes, while types highlighted in green represent (sometimes only approximately) floating point values (i.e., capable of representing fractional values).
C++ is a case-sensitive language; the data type names must all be in lowercase letters.
The modifiers signed and unsigned may be applied to the integer types as well. Signed types can represent positive and negative values; unsigned types only represent non-negative values. Most data types are signed by default, but the char type is ambiguous.
There is a further ambiguity with the sign of a character. char is signed on some computers but is unsigned on others (i.e., the hardware determines the signedness of a char), with signed being the most common today. This ambiguity can cause problems, for example, when reading a file one character at a time. Some input functions return a symbolic constant named EOF (end-of-file) when there are no more characters to read. EOF is often just a -1, which an unsigned char cannot represent. To solve this problem, many library functions that deal with characters do so as integers, and C++ automatically converts between an int and a char (both directions) without programmer intervention.
Modern compilers are beginning to recognize additional types; for example, see the types recognized by Microsoft Visual Studio.
Constants
Constants are fixed values that do not change over time and are common in most programs. The compiler uses two simple rules and a few symbols to determine the data type of constants appearing in a program:
Numeric Data Type Rules
Numeric constants that do NOT contain a decimal point are type int by default.
Numeric constants that DO contain a decimal point are type double by default.
Given a specific constant value, this isn't a question of what data type the constant can fit into but rather what type it is. For example, 3.14 can fit into a float, but the compiler makes it a double; 13 will fit in a short, but the the compiler makes it an int.
Example
Comment
10
The compiler automatically treats numeric values that do not have a decimal point as type int
10L
The L instructs the compiler to treat the constant as type long
10U
The U instructs the compiler to treat the constant as unsigned
10.0
The compiler automatically treats numeric values that include a decimal point as type double
10F 10.0F
The F instructs the compiler to treat the constant as type float
0xAB
The 0x instructs the compiler to treat the constant as an int in hexadecimal (i.e., base 16); hexadecimal numbers can use the digits 0 - 9 and a - f or A - F; hexadecimal numbers are treated as unsigned by default
067
The leading 0 instructs the compiler to treat the constant as an int in octal (i.e., base 8); octal numbers can only use the digits 0 - 7, and are treated as unsigned by default
'a'
The single quotation marks instruct the compiler to treat the constant as type char. Note that only one character may appear between single quotation marks (see "Escape Sequences" at the bottom of the next page)
"hello"
The double quotation marks instruct the compiler to treat the constant as a string (called a string literal or string constant). Although a string containing only one character looks similar to a character constant (e.g., "x" and 'x'), their representation in a computer is very different.
1.23e20 1.23e-20
Scientific notation is used for very large and very small numbers. The examples mean 1.23×1020 and 1.23×10-20 respectively
Constant examples. The examples demonstrate the C++ syntax establishing a constant value's data type.
Variables
A variable is a named region of memory. The region's size (i.e., the size or the amount of memory reserved) depends on the variable's data type, as illustrated in Figure 1. The contents of memory, and therefore the value stored in a variable, can change or vary over time. Variables have three essential characteristics:
The characteristics of a variable. An abstract representation or mental model of a variable with its three characteristics (reading from left to right):
Name
Programmers name each variable in a program. The name (formally known as an identifier or symbol) must follow a few simple rules (listed at the bottom of the page). Although programmers can access variables by name, machine code only accesses them by their address. As a part of code generation, the compiler maps the variable's name to its address.
Content
A variable is a container, so it naturally has content - the data currently saved in the variable. A variable's contents can change or vary over time - hence the name variable.
Address
Variables occupy space in a computer's main memory, so they have a memory address. For multi-byte data, the variable's address is the address of the first byte. Programs and programmers typically display addresses in hexadecimal.
int counter;
double balance;
char grade;
Variable definition examples. Programmers must provide two pieces of information when defining a new variable: (a) a data type and (b) a name. The compiler uses the data type to determine how much memory to allocate and how to interpret the contents of that memory. Programmers typically have no control over the location or address of the variable. When a program defines a variable, its first operation with the variable must initialize it - store its first or initial value.
Executable machine code is based solely on the address of a variable in memory. As part of the compilation process, the compiler maps the variable name to the variable's address. When a program uses a variable, it may require either its content or its address in memory. When a variable name appears in a program, how does the compiler "know" which to use? The answer is that the correct value is determined by where the variable appears in the code.
If the variable name appears on the left side of an assignment operator or as the target of an input
statement (e.g., cin >> var ), the compiler replaces the name with the address of the variable. In essence, the compiler is storing the result of an operation at the memory location represented by the variable's name.
If the variable name appears on the right side of the assignment operator or in an output statement
(e.g., cout << var ), the compiler replaces the name with instructions to load and use the value stored in the variable (i.e., stored in memory at the address represented by the variable's name).
Context sensitive interpretation. The compiler determines how to use a variable name - as its contents or address - based on where programmers use it in a statement (i.e., on its context).
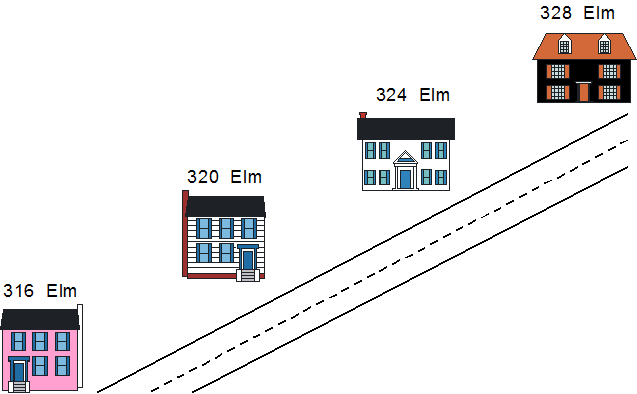
Houses along a street provide a simple metaphor for variables. Each house has someone living in it, but the current occupants could move out, and new people could move in. Baring a catastrophe (like a tornado throwing the house over a rainbow into Oz), the address remains unchanged as people move in and out. Furthermore, the address of a given house is a function of where that house appears on a given street within a given city. Each house has a unique address. The addresses of adjacent houses differ only a little; the addresses of separated houses differ by a greater amount.
Houses on a street as a metaphor for variables in memory.
A street with houses makes a nice metaphor for variables laid out in memory. Like houses, each variable has a unique address that increases as you move along the street or through memory. Furthermore, house addresses usually increase by more than 1 - they increase by 4 in this example.
Computer memory is byte-addressable, meaning that an address of n + 1 is one byte higher in memory than is n. An integer is 4-bytes long on many computers, so a sequence of four integers in memory would have addresses four bytes apart, similar to the house addresses in the illustration.
Scope
Programming languages allow programmers to name different programming elements or entities such as variables, functions, classes, etc. Scope is the location in a program where a specific name is visible and accessible. More formally, programs bind names to entities, and scope "is the region of a program where the binding is valid." For now, we focus on variable scope. Saying that a variable "comes into scope" or "goes out of scope" means that program execution enters or leaves the area in a program where the statements can use the variable - that is, program execution enters or leaves a variable's scope.
Figure 3 (above) illustrates the three variable characteristics: an address, a name, and the current content. Scope is that part or region of a program where the name and the address are bound or connected - that is, where the name maps to that specific address. The concept of binding a variable name to an address leads to two scoping rules:
Variable names must be unique within a scope, meaning a name can't simultaneously refer, bind, or map to two different addresses or memory locations.
However, one address can map to more than one name - that is, one memory location can simultaneously have more than one name. Generally, programs define each name in a different scope
Variable scoping rules. The rules governing variables and their scope are few, simple, and immutable.
Memory Allocation and Deallocation
Modern computers typically have many gigabytes of main memory. But not all that memory is available for a program to use: all programs running on a computer, including the operating system, must share the computer's memory. The operating system (OS) manages all a computer's resources, including memory. The OS manages memory by allocating it to programs as needed and deallocating it when it is no longer needed. Programs further manage the memory allocated to them by allocating and deallocating it for new variables as needed. Chapter 4 explores how a program manages its memory.
Storage Modifiers: The auto And static Keywords
C++ provides two modifiers that alter how the memory needed to store a variable is allocated and managed: auto and static. (The auto keyword is overloaded to implement Type Deductions, see below.) Variables are automatic (i.e., "auto") by default, and so, in this context, the auto keyword is rarely used in practice. Alternatively, the only way to make a variable static is by including the keyword in the definition: static int counter;.
The computer allocates space for automatic variables1 in its main memory or RAM. It allocates the memory automatically when the variable comes into scope and frees or deallocates it when it goes out of scope. Furthermore, C++ is a block-structured language, which means that a pair of opening and closing braces define a block. Each new block forms a new scope, and because blocks may be nested, scopes can be nested much like the layers of an onion. The program allocates memory for an automatic variable defined in a block when it enters and executes the code in the block. It deallocates the memory when execution moves outside the block, past the closing brace.
Alternatively, the memory needed to hold a static variable is allocated when the program is first loaded into memory and remains allocated throughout the program execution. Static variables retain their contents even when the name goes out of scope. So, the memory allocated for a static variable remains usable when the variable name is not in scope. The variable name always follows the scoping rules, but the memory allocation/deallocation rules for static and automatic variables differ. This observation has useful ramifications related to functions and pointers that we will explore later in Chapter 4.
Scope vs. Memory Allocation
Scope and memory allocation are related, but they are not the same. The connection between scope and memory allocation is very tight for automatic variables. The computer allocates the memory needed to store an automatic variable when the variable comes into scope and deallocates it when the variable goes out of scope. However, static variables illustrate the distinction between the concepts. The operating system allocates memory to store static variables when it loads the program into memory. While the program runs, static variables come in and go out of scope without deallocating their memory or losing their saved data. The program deallocates memory for static variables only when it terminates. We'll return to scope and memory allocation in chapters 6, 7, and 8.
Programmers often use static variables to create functions that retain or "remember" values from one call to the next. For example, imagine a function that defines a static variable. The variable name has local scope - the variable is only accessible inside the function. However, when the function returns, the program retains the variable's memory and saved value. So, if the function returns the address of the memory, the program can still access the stored data. We explore how and why we do this in chapter 6.
Initialization
A variable is said to be "initialized" when assigned its first or initial value. Initialization occurs at three times or places:
when the variable is defined (simultaneous definition and initialization)
when the program prompts for and the user enters a value
by assignment following the definition - often by a calculation
Formally, the value stored in an uninitialized variable is said to be undetermined. Informally, an uninitialized variable is said to contain garbage (memory is never empty, so an uninitialized variable contains the unspecified or random bits already present in memory). It is possible, but not required, to initialize (i.e., assign a value to) a variable in the same statement that defines it. The following figure illustrates the three ways of simultaneously defining and initializing a variable.
int maximum = 100;
int maximum (100);
int maximum {100};
(a)
(b)
(c)
C++ variable initialization syntax. Defining and initializing a variable are two distinct tasks. But, as demonstrated in the three examples illustrated here, the two tasks may be combined into a single statement.
Copy initialization
Constructor initialization
Uniform initialization
(a) is the most common and all you need to know for now.
int maximum; // variable definition
maximum = 100; // variable initialization
int maximum = 100;
(a)
(b)
int minimum;
cout << "Please enter the minimum: ";
cin >> minimum;
int width;
int height;
int area;
// read in the values for width and height;
area = width * height;
(c)
(d)
Variable initialization examples. A variable definition requires a data type and a variable name. Although it is possible to define and initialize a variable in a single statement, both steps represent distinct operations - compare (a) and (b).
A variable definition followed by a variable initialization - each operation takes place in a separate statement
Variable definition and initialization completed in a single statement
Variable defined and then initialized with an input operation (i.e., a prompt and read)
Variable defined and then initialized by a calculation
Steps to using a variable:
Define the variable
Initialize the variable (i.e., store the first value into it) by an assignment or by data input
Use the variable in some way
You may replace the value in the variable and use the variable repeatedly.
Steps to getting a drink:
Get a glass from the cupboard
Fill the glass with water
Drink the water
You may fill the glass and drink as often as you like; you may also fill the glass with something other than water.
Variables analogized as a drinking glass. The figure compares the steps a program must take to use a variable with the more familiar steps needed to drink from a glass. In both examples, the order of the steps is necessary for the success of the operations.
Although programmers and a great deal of existing code continue using the #define directive to create symbolic constants, it is an older mechanism. The preprocessor implements the directive as a simple text substitution, bypassing the compiler component's syntax and type checks. C++ and ANSI C programmers can use the const keyword to implement fully checked symbolic constants.
const int MAX = 100;
const double PI = 3.14159;
const char DELIMITER = ':';
const string LABEL = "Exit";
Creating symbolic constants with const. The const keyword creates a "variable" whose value the compiler does not allow to change. The const keyword allows programmers to create symbolic constants of any valid data type.
Type Promotions
Data types are fundamental to how a C++ program operates. From the above discussion, it's clear that constants and variables have types. But constants and variables are just specific kinds of expressions, and indeed, all expressions have a type. When operators and sub-expressions form an expression, the compiler generates code to automatically convert each sub-expression to the widest type in the expression, an operation called type promotion. The dynamic range of the type determines its width. For example, from Figure 1 above, long and float are both typically four bytes long, but a variable of type float can hold much larger and much smaller values than can a long, so a float has a wider dynamic range than a long.
2 * 3.14
int counter(100);
double avogadros { 6.022e23 };
avogadros / counter;
(a)
(b)
Type promotion examples. Type promotions are an automatic, compiler-provided conversion from one data type to another. Generally, the conversion is from a narrow type (small range of values) to a wider type (greater range of values). However, C++ automatically converts between char and int.
2 is type int, and 3.14 is type double. The compiler cannot directly operate on mixed types, so it promotes 2 to a double. The result of the multiplication operation is a double-valued expression.
counter is defined as an int and constructor-initialized to 100; avogadros is defined as a double and is initialized to 6.022 × 1023. The compiler promotes counter to type double before calculating the quotient. The result is a double-valued expression.
Type Deduction
In much the same way that the compiler can determine the best data type to represent an expression accurately, it can also infer or deduce an appropriate type for a variable. The ANSI C++11 standard extended the auto keyword for this purpose; the ANSI C++14 standard added a new keyword, decltype, that deduces a variable's type with a different syntax.
int counter = 100;
//int counter(100);
//int counter{ 100 };
auto max = counter;
Type deduction examples. In both examples, programmers may define and initialize counter using any of the three illustrated techniques.
The type of max is deduced from the type of counter and max is also initialized to 100
The type of max is deduced from the type of counter, but without initializing it
Legal Identifiers
An identifier is the name that a programmer gives to an element of a program. Variables are the only namable programming element introduced so far. Eventually, we'll study other namable elements, like functions and classes. Regardless of what the programmer is naming,
the rules for creating legal identifiers or names are the same.
May be any length
Are case sensitive ( Counter is not the same as counter )
Must begin with a letter or an underscore ( _ )
Subsequent characters may be letters, digits, and underscores (but no other characters)
Cannot be a keyword
May only be defined once in a scope
Should avoid library function names (although you can use library function names, the practice can be confusing)
Identifier Rules. Programmer-created identifiers or names must conform to a few rules and recommendations.
1 The term automatic variable was introduced with the ALGOL programming language and is generally applied to all languages derived from it, including C++. A more common term is local variable; a less common term is stack variable. We'll cover the underlying principles justifying these terms in later chapters. (See Glossary: Automatic variables for more detail).