Every block defines a new scope - the region in a program where a name (identifier or symbol), often a variable name, is visible and accessible. Although blocks can be nested arbitrarily deep, there are only three primary or named levels of scope:
Local: inside a function
Class: inside a class (i.e., an attribute or a member variable)
Global: outside all functions and classes
Programmers often classify variables by their scope: they define global variables in global scope, local variables in local scope, and class variables in class scope. We defer our discussion of class scope and class variables until chapter 9.
Local Variables
local variable, local scope, automatic variable, stack frame, runtime stack
Local variables, including the function's parameters, are defined in a function. Programs initialize parameters with the values passed in as part of the function call. Programmers may explicitly initialize the remaining local variables with an assignment that is part of the variable definition, but doing this is not required.
int read()
{
int count = 0;
while (there are lines in the file)
{
read a line;
count++;
}
return count;
}
Defining and initializing a local variable.
The program reinitializes variables whose definition includes an explicit initializer each time it enters the function. Variables without an explicit initializer contain "garbage" until the first assignment operation. By default, local variables are automatic variables, which means that the program automatically allocates their memory on the stack when entering the function and deallocates it when the function terminates.
The stack relies on a simple algorithm to manage its memory: A function call pushes a data structure called a stack frame onto the runtime stack. The stack frame corresponds to a single stack element (i.e., one colored box in the stack animations). The stack frame stores the return address (i.e., the address where execution resumes when the function ends) and provides the memory for all the function's local variables. The program pops and discards the stack frame when the function ends and returns.
void function(int u, int v)
{
int x;
int y;
int z;
.
.
.
}
(a)
(b)
The relationship between a function call and a stack frame.
Local variables are those defined inside a function, including the function's parameters (u and v in this example). Unless explicitly made static, local variables are automatic.
Whenever a program calls a function, it pushes a stack frame onto the runtime stack. The stack frame provides memory for all local variables and saves the function's return address. When the function ends, the program resumes execution with the instruction at the return address.
Function Scope: Call Vs. Definition
function scope, function call, function definition
In a previous section, we learned that function arguments, the data passed into a function, are expressions. Expressions can contain sub-expressions formed by variables and operators, and some of those operators can change the values stored in the variables. Discerning a variable's scope is essential to understanding the behavior of function calls that contain argument-modifying operations.
Calling Scope
Alternate Call
Function Scope
int a = 5
int b = 10;
function(a++, b++);
int a = 5
int b = 10;
function(a, b);
a++;
b++;
void function(int x, int y)
{
...
}
(a)
(b)
(c)
Function-call vs. function-definition scope.
Scope is the location in a program where a name is visible and accessible. This example uses the auto-increment operator to explore some effects of scope on variables passed in function calls. The program defines the variables a and b in the scope where it calls the function, and the local variables x and y in the function's scope.
The post increment operators first "use the values" stored in a and b, and then increment the values. So, the call passes the initial values, 5 and 10, to the function: x = 5 and y = 10. Following the function call, the increment operators update the values stored in a and b to 6 and 11, respectively. The increment operations occur in the same scope as the variable definitions. So, the values 6 and 11 remain after the function call finishes.
Expanding the code of example (a) clarifies the order of operations while exhibiting the same behavior. How would you rewrite this code if we changed the post-increment to pre-increment? 1
The C++ syntax doesn't allow us to increment x and y in the function header, but we can in the function body. Incrementing x and y, x++ and y++, only changes the local variables. After the function returns, x and y go out of scope, discarding the change.
static Variables
static variable, local static variable
Automatic and static variables lie at opposite ends of the memory allocation spectrum. The static keyword does not alter a variable's scope, but it does alter its behavior in two important ways:
Programs only initialize static variables once when the operating system loads them into memory (not on each function call like automatic variables)
Local static variables retain their saved values between function calls, which functions can use when called again.
These features are pivotal in the following C++ function's operation.
double random()
{
static double x = 0;
x = x * (x + 1) % 2147483648L;
return x;
}
Using a static variable.
This function implements a simple pseudo-random number generator based on an algorithm first developed by Donald Knuth. If the program initializes x to 0 for each function call, the function will always return the same value, which is not at all random (not even pseudo-random). But for each call, the function changes x and retains the new, updated value in the static variable, where it's available to the next function call.
Memory Allocation and Variable Initialization Summary
memory allocation, variable initialization, auto variable, static variable
Two features distinguish auto and static variables: when the variable's memory is allocated and deallocated, and when an explicit initialization takes place.
auto
static
Example
int minimum = 100;
static int maximum = 100;
Allocation
Every time the function runs
Once, when the program loads
Initialization
Every time the function runs
Once, when the program loads
Deallocation
Every time the function returns
Once, when the program ends
auto vs. static variables.
Global Variables
global variable, variable initialization, zero-equivalent (definition)
Programs define global variables outside any function or class. If the programmer does not explicitly initialize global variables, the compiler automatically initializes them to their zero-equivalent. Zero-equivalent values are 0 for integers, 0.0 for floating-point types, false for Booleans, and nullptr for pointers.
The initialization operation for explicitly initialized global variables only occurs once when the operating system loads the program into memory for execution.
Global Variables: Use and Pitfalls
global variable
Global variables are always visible from the point of their definition to the end of the defining file. Programmers typically use global variables in three situations:
Whenever two or more functions must share data. Classes reduce the need for global data by allowing member functions to share class-scope data.
When a function creates or uses a large amount of discrete data (individual variables) that are not easily passed to or returned from the function. Arrays and objects (instances of structures and class) make it easier for programs to move large data blocks.
When data is exchanged (passed to or returned from) between functions separated by many intervening function calls and where the intervening functions do not use the data. The following figure illustrates this situation.
functionA()
{
// data defined here as a local variable
functionB(data)
}
functionB(data)
{
functionC(data)
}
.
.
.
functionY(data)
{
functionZ(data)
}
functionZ(data)
{
//data used here;
}
// data defined here as a global
functionA()
{
functionB()
}
functionB()
{
functionC()
}
.
.
.
functionY()
{
functionZ()
}
functionZ()
{
//data used here;
}
(a)
(b)
Using global variables to eliminate function arguments. A situation sometimes seen in C programs.
Function A defines data and passes it through a sequence of function calls to a function, Z, that uses it, but functions B through Y do not use it. In this situation, data is passed (copied if passed by value) through many functions.
Making the variable global eliminates the long sequences of passing data through functions that do not use it.
C++ provides a cleaner, less error-prone solution by making the functions members of the same class. Classes allow some functions to share data while "hiding" it from the rest of the program.
int var = 10;
void function()
{
cout << var << endl;
}
int var = 10;
void function()
{
int var = 5;
cout << var << endl;
}
int var = 10;
void function()
{
int var = 5;
cout << ::var << endl;
}
(a)
(b)
(c)
Variable name confusion and resolution. C++ does not allow programmers to define multiple variables with the same name in the same scope. However, they can define variables with the same name in different scopes, even when they overlap. In the case of overlapping scopes, the compiler searches the nearest scope first and continues widening its search to surrounding scopes until it finds a matching definition.
The compiler begins searching for var in the function's scope. Failing to find a matching definition, it widens its search to the next scope. It finds a definition and initialization in global scope, printing 10.
The compiler searches for and finds a definition and initialization for var in the function's scope. It accesses the local variable and prints 5.
The scope resolution operator (red) causes the compiler to skip searching the function's local scope. It finds and uses the variable named var defined in global scope, printing 10.
Modules And File Scope
module, file scope
Strictly speaking, variables defined outside of functions or classes only have file scope: they are only visible and accessible from the point of their definition to the end of the defining file. But all that is necessary to expand file scope to global - making the variables visible throughout a program - is an extern declaration in each file desiring access to the variables. To easily make a variable truly global, place the extern declaration in a header file and #include it in the program's source code files.
C programmers limited the scope of "global variables" by creating modules defining file scope variables. An overloaded application of the static keyword allows programmers to limit the scope of otherwise global variables to the defining compilation unit (i.e., file). Functions defined in the same file as the file scope variables are the only ones allowed to access them. Programs attempting to access a file scope variable from another file will cause the linker (or loader) to abort with an "unresolved external symbol" error.
File1.cpp
File2.cpp
int counter = 100;
static int size = 50;
void increment()
{
counter++;
}
extern int counter; // declaration
int report()
{
return counter;
}
(a)
(b)
Controlling scope with the extern and static keywords.
counter and size are file scope variables. However, programmers can easily make counter global.
An extern declaration in another file allows it to access and use a global variable defined elsewhere. Note that the following statements are NOT legal:
extern int counter = 25; (may not initialize a variable declaration)
extern int size; (may not access a file scope only variable)
Although C++ supports modules, classes provide the same benefits and are far more flexible.
Use global variables judiciously
Global variables are a sometimes necessary evil in C programs, but they have been the cause of countless programming problems, so programmers should use them sparingly. Before using even one, be sure you have explored all the other options and can justify using a global. Fortunately, classes have largely eliminated the need for global variables in C++, and their use in contemporary programs, aside from very specialized ones, is quite rare. (The C programming language does not support classes, so C programs sometimes need global variables.)
Coupled Functions
coupled functions, function coupling
So, what's the big problem with global variables? Functions that share global data are said to be coupled. Coupling implies that the functions cannot be tested or validated in isolation. Coupled functions must be tested and debugged as a group because a change to the data made by one function can affect another function that shares it. This requirement makes working with coupled functions more difficult and error-prone.
Furthermore, coupled functions are often very fragile. One function can make a small, innocuous change to the data that causes a catastrophic failure in a coupled function. The likelihood of these conflicts increases with data size and the number of coupled functions, until it becomes challenging to maintain the program. Changes to shared data ripple outwards, crossing file boundaries and affecting code that programmers don't intend to change, silently introducing bugs into previously working code.
Function coupling increases the complexity of a program. And that complexity increases at a greater rate than the rate of function addition. That means doubling the number of coupled functions more than doubles the program's complexity. The complexity continues increasing to the point where the system becomes so complex that further growth is impractical.
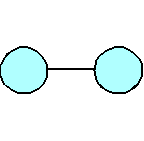
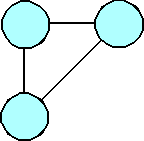
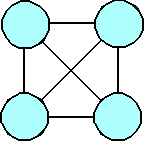
(a)
(b)
(c)
An abstract representation of function coupling.
To gain a qualitative sense of the relation between coupling and complexity, let the circles in the figures represent the coupled functions in a program. The connecting lines are an abstract representation of the coupling of the functions, and the number of lines (very loosely) represents the level of complexity. As the number of coupled functions increases, so does the number of connecting lines and, therefore, the level of complexity. The level of complexity increases faster than the program adds coupled functions.
A program with two coupled functions exhibits a relatively low level of coupling and a correspondingly low level of complexity.
Adding one coupled function increases the level of complexity.
Adding another coupled function further increases the level of complexity.
1 Answering this question for yourself is a good way to test your understanding of the pre- and post-increment operators. The "Meaning" column in the table describing the auto-increment and decrement operators suggests how to rewrite the code in question.
int a = 5
int b = 10;
a++;
b++;
function(a, b);
When not embedded in a more complex expression, a++ and ++a are equivalent. The key is to notice the relative order of the increment operations and the function call.