Real-world programs are often large, ranging from thousands to millions of lines of code, making managing them in a single file impractical. Furthermore, maintaining a large program in a single file forces programmers to duplicate code common to multiple programs (user interface code in office suites, for example). Our previous programs have been small and only relied on simple, fundamental data types like int, char, and double, which the compiler "knows" about intrinsically, making them appropriate for a single-file implementation. In this section, we take a transitional approach, beginning with structures demonstrating the value of header files and concluding with small programs illustrating the organization of multi-file programs.
Structures And Memory
Imagine that we can look into a computer's memory. We see electrical circuits at the most fundamental, physical level, which doesn't help us understand how programs organize structures in memory. Moving up to the next level of abstraction, we can see a vast sea of 1s and 0s, which is better but still not what we need. Continuing our climb to the next level of abstraction, we see a stream of bytes, which is a helpful level for our next task. A program makes sense of the bytes by partitioning them into the discrete units that form the backbone of a program. For example, a program can assemble eight bytes to form an int or a machine instruction and sixteen bytes to make a double. In the case of structures, the partitioning is more complex.
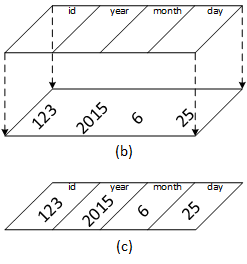
When data is copied or otherwise moved around in a program, the program treats it as a starting point in memory (i.e., an address) and a size (measured in bytes). The compiler already knows that there are eight bytes in an int and sixteen bytes in a double, so partitioning those variables is relatively straightforward. But what about a structure? Two structures can have a different number of fields, different kinds of fields, or both. So, how big is a structure, and where are the boundaries between the fields? Figure 1 illustrates how a structure partitions an otherwise formless block of bytes in memory to form distinct fields.
struct person
{
int id;
int year;
int month;
int day;
};
.
.
.
person p = {123, 2015, 6, 25 };
(a)
A struct is a template that partitions memory contents into distinct variables.
A structure specification describes how a program partitions memory to form distinct variables. The variable definition instantiates a structure object, allocating memory. The initialization saves values in the object's fields.
The bottom rectangle represents a memory region containing bytes of data, grouped as four integers for our convenience. Imagine a structure (the top rectangle) slowly lowered over the data.
The structure partitions the bytes into four distinct variables or structure fields.
Now, imagine what happens if a program consists of two parts, each in a different file, and each "seeing" a different specification for the same structure. For example, in some parts of the world (and in computer programs), it is common to express a date as year, month, and day, while in other places (the U.S., for example), it is common to describe a date as month, day, and year. Two different programmers could easily write a date structure specification with the fields in different orders. The following program, which compiles and runs, illustrates what happens:
File1.cpp
person.cpp
struct person
{
int id;
int year;
int month;
int day;
};
void print(person); // declaration
int main()
{
person p = {123, 2015, 6, 25 };
print(p);
return 0;
};
#include <iostream>
using namespace std;
struct person
{
int id;
int month;
int day;
int year;
};
void print(person temp)
{
cout << "ID: " << temp.id << endl;
cout << "Month: " << temp.month << endl;
cout << "Day: " << temp.day << endl;
cout << "Year: " << temp.year << endl;
}
(a)
(b)
ID: 123
Month: 2015
Day: 6
Year: 25
(c)
The problem with inconsistent structure specifications.
The first file specifies a structure named person and creates an object based on it. The code initializes the object and passes it to the print function defined in another file.
The other file also specifies a person structure but with the fields in a different order. The print function receives the person object sent by the function call in the first file. However, when print displays the structure's fields, it interprets them based on the local specification, a different specification than used to fill the object's fields.
The program's output. The inconsistent field order between the two structure specifications causes the program to misinterpret the data stored in the structure object.
This two-file program compiles and runs but produces incorrect output. Although the output is not what the programmer wants or expects, the displayed values are still recognizable from the initial values, but only because the three date fields are the same type. If the fields were different types with different sizes (and therefore had various boundaries), the overlaid structure would not match the original field boundaries, and the error would garble the output entirely.
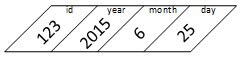
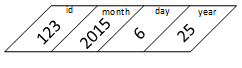
Original Structure
Extracting Structure
struct person
{
int id;
int year;
int month;
int day;
};
struct person
{
int id;
int month;
int day;
int year;
};
(a)
(b)
The effect of changing struct specifications.
A program's source code accesses a structure's fields by name, but the compiler maps each field name to a memory address1. Once a running program creates a structure object, it's just a sequence of bytes in memory. It uses pointer or address arithmetic to access (save or retrieve) the data stored in each field. The compiler uses the structure field names to calculate the addresses of the fields to extract the data held in them. This process works if the compiler uses the same structure specification to create the object and extract data but fails otherwise.
The layout of a structure object that "sees" a specific structure specification. Imagine a program passing the object as an argument to a function defined in another source code file.
A function receives an object laid out using one structure specification but extracts the data using a different specification.
Header Files and Consistent Structure Specifications
The likelihood of a transposition error, as illustrated above, increases with rising numbers of:
Fields in the structure
Structures in a program
Files in a program
Programmers working on different program files
In addition to transposition errors, programmers can add or delete fields or misspell their names. C++ provides a way of minimizing the errors arising from mismatched structures by eliminating duplicate specifications.
person.h
struct person
{
int id;
int year;
int month;
int day;
};
void print(person); // declaration / prototype
File1.cpp
#include "person.h"
int main()
{
person p = {123, 2015, 6, 25 };
print(p);
return 0;
};
Header files and multi-file programs.
The easiest way to avoid the problems caused by multiple, non-matching structure specifications is to eliminate all but one specification. Nevertheless, each file that uses the structure must "see" the specification. Programmers solve this problem by putting the specification in a header file and including it in the source code files with the #include directive as demonstrated above. This organization follows the Bottom-Up Implementation strategy described earlier.
File1 is a client using the person structure; together, person.h and person.cpp form a server or supplier.
Typically, only one structure is placed in a header file, making it easier to reuse.
The header file is typically named after the contained structure.
The header file name is enclosed with double quotation marks, denoting that it is collocated with the source code files (i.e., in the same directory as the .cpp and the .h files).
The header file contains a function declaration: void print(person);. The next chapter explores these in greater detail.
Using a header file reduces the tedium of copying and pasting the struct specification from one source code file to another. More importantly, it creates a single point of modification should you ever need to add or remove any fields or make any corrections. Imagine how easy it would be to miss updating a specification in one file if the program has tens or hundreds of copies of the structure spread throughout hundreds or thousands of source code files!
Caution
It is tempting to use the preprocessor to combine the source code files by #including one source code in another:
#include "person.cpp"
But this negates one of the advantages of spreading a program over multiple files and is rarely done in practice. Rather than #including one .cpp file inside another, let the linker or loader combine the files.
1 For those who are interested, the computer accesses each structure field by adding an offset to the object's beginning memory address. The compiler calculates the offset for field n by summing the sizes of fields 0 through n-1 and adding the sum to the object's address. For example, assuming the original structure's field order and letting p be an instance of the person structure, the compiler calculates the addresses for each field as: