function (definition), function binding (definition), function call (definition), black box, white box, client (definition), supplier (definition), execution path, function decomposition, argument, parameter
A function is a named and parameterized set of reusable statements that cooperate to perform a task. The compiler translates the function's statements to machine code, stores it in a distinct memory location, and maps the function's name to that memory address. Formally, mapping a function's name to it address is called function binding. Programs use functions by calling them, passing zero or more arguments or data elements to their parameters. The function call "jumps" to the function's address that is bound to the function's name, executes the machine code there, typically operating on the arguments passed in the call, and returns to the statement following the call when the function ends. Along with variables, functions are among the oldest and most important programming constructs in imperative programming languages.
(a)
(b)
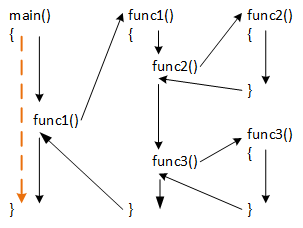
Visualizing function calls.
Programmers can view a function call as another sequential statement performing a single, well-defined operation on a set of input arguments. In this view, they treat it as a black box, "hiding" its internal operations. Alternatively, they can view a function call as interrupting the "normal" sequential instruction flow, "jumping" from the call to another group of instructions in a function, and returning when the function finishes. This view treats a function as a white box by examining its internal operations, and the arrows illustrate a program's execution path for a given set of inputs.
It's often convenient to imagine the code calling a function as a client that uses the function's service. Following this perspective, programmers imagine a function as a supplier that provides a service. The pictures illustrate that when a client calls a function, execution jumps to the function's instructions and returns to the statement following the call when the function ends.
The dashed gold arrow illustrates the view of the function call as a simple, sequential statement. The previous examples of the sqrt and pow functions demonstrate this view. The solid black arrows show how the function calls jump to different memory locations, interrupting the program's sequential execution, and return when the function ends. The solid arrows also demonstrate that one function can call another, and that the functions return in the reverse order of their calls. When one function calls another (for example, func1 calls func2), the first function remains active in the sense that it remains in memory and any variables it defines retain their stored values. Given the function call chain:
main() → func1() → func2()
func1 operates as a supplier to main and as a client of func2.
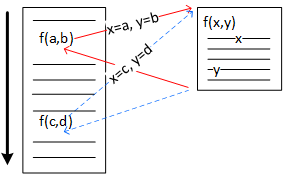
A program may call a function many times, passing different data through the call's arguments (e.g., a, b, c, and d) each time. Passing data from a function call's arguments to the function's parameters (x and y) effectively performs an assignment operation: x=a, y=b, x=c, and y=d. Each function call reuses the same machine code but with potentially different data.
Although functions impact programming in many ways, their most important contribution to software development is their influence on how developers conceptualize or think about problems and how they implement the software that solves them. Trying to understand a large and complex problem in its entirety is both overwhelming and counterproductive. Software developers typically decompose (break down) the problem into successively smaller units until they reach a conceptual unit that is sufficiently small and simple enough to understand. Once they understand the smaller units, they build up increasingly complex units from them.
Similarly, software design based on the procedural programming paradigm proceeds by representing or mapping parts of the problem to corresponding functions. Software designers decompose (break apart) functions into increasingly smaller, simpler functions. Unfortunately, there is no "magic" recipe for doing a functional decomposition, and there is no perfect size for the functions at which we stop the decomposition. Developers continue to break down the functions until they reach a point where they can understand and implement each function conveniently.
Mapping parts of a problem to different functions implies that we can use functions to think about and represent abstract problems. As Jonassen suggests, we can then manipulate those functions as part of our problem-solving process. Finally, we implement (program) those functions to realize a working solution to the original problem.
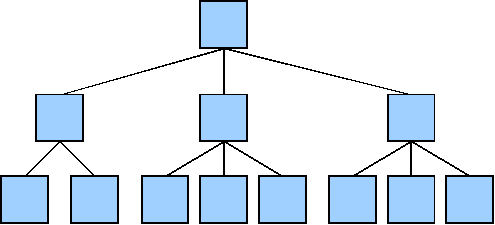
An abstract representation of a functional decomposition.
Functional decomposition breaks down complex functions into successively simpler ones. The simple functions isolate and complete some of the original function's tasks. Decomposition helps programmers manage complexity and often leads to more general functions they can reuse in other programs. We can view decomposition as an inverted tree, with each box representing a function that calls the successively smaller, simpler functions that lie below it in the diagram. The leaf functions are typically small and simple, performing only single, well-defined tasks. Programs can also call functions in ways that result in cycles in the function-call diagram.
Software developers typically take one of two paths to implement the functions.
Bottom-Up Function Implementation
bottom up, driver (definition)
Bottom-up implementation begins with the leaf functions at the bottom of the tree. Once programmers implement the leaves of a sub-tree, they can implement the sub-tree itself. If the functions only rely on data passed in through the argument list, it is possible to validate these functions independently of the rest of the program. Programmers use a driver or a set of driver programs to validate each function. A driver is simply a program that calls a function, sends appropriate test data as arguments, and in some way verifies that the returned values or effects of the function are correct. The bottom-up strategy is demonstrated by both the Time and the American example programs presented in the last chapter.
For contemporary software development, the bottom-up approach is appropriate for small programs or for implementing the core functions of larger, more complex programs. However, the bottom-up approach is incompatible with incremental delivery for large, dynamic programs. Software developers practice incremental delivery by initially delivering a system with essential core features and then adding and delivering enhancements over time.
void function(int x, int y, int z)
{
.
.
.
}
int max(int x, int y)
{
return (x > y) ? x : y;
}
int main()
{
function(10, 20, 30);
int a = max(100, 200);
cout << a << endl;
return 0;
}
(a)
(b)
Bottom-up implementation.
Programmers implement functions from the bottom of the tree to the top, beginning with the functions that do not call or rely on other functions. Programmers write a driver function that calls and tests these functions, then discard it once testing and validation are complete. Driver functions are temporary and do not contribute to solving the program's problem, so it's okay to hard-code test values in them.
An example of simple leaf functions.
A driver program.
Top-Down Function Implementation
top down, incremental delivery
Top-down implementation begins with the high-level functions. Function stubs replace the smaller, lower sub-functions. A stub is nothing more than an empty function where the body contains just enough code to allow the function to compile without error. For example:
void print(int x, double y)
{
}
double pow(double x, double y)
{
return 1.0;
}
Stub functions in a top down implementation.
Programmers implement the functions highest in the decomposition or tree first. Whenever one of these functions needs to call a function lower in the decomposition, the programmer creates a stub function. Stub functions contain just enough code to allow a program to compile and run - they are, in effect, temporary placeholders. Functions that return a value (i.e., that do not have void as the return type) must include a "dummy" return statement (e.g., return 1.0;) in the body for the program to compile. The bodies of stub functions are replaced by fully operational statements (and any dummy returns are discarded) as development continues downwards from the top of the decomposition tree.
Top-down implementation allows software developers to practice incremental delivery. Large software systems typically provide many related features. Programmers can implement a minimal core set of features that form a deliverable product capable of doing practical work. Programmers regularly enhance the product with additional features and deliver incremental improvements to customers and clients. Incremental delivery allows developers to gain market share and gather feedback on what matters most to customers.