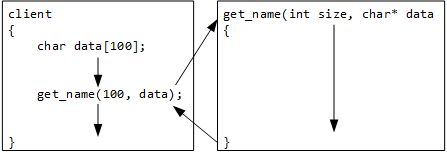During my career as a software engineer, I periodically interviewed for new positions. Interviews, especially second interviews, often included engineers who asked technical questions. During two interviews, at different times and with different companies, I was given the following function, with various distracting statements in place of the ellipses, and asked, "What's wrong with this code?" 1 Can you identify the problem?
A logical scope error.
The function is syntactically correct but has a logical error, making its behavior unpredictable. Focusing on the given information rather than speculating about possible omissions, we can dispense with suggestions often offered by new programmers:
char name[100]; is a valid character array definition. The getline adds the null-termination character, making the array a valid C-string.
The return type, char*, matches the returned expression, return name;, because name (without any brackets) is a character pointer.
Entering fewer than 100 characters is not an error - C-string functions ignore any characters following the null termination character.
Entering more than 100 characters is not an error - the getline function will read at most 99 characters, leave a space for the null terminator.
Although the initial problem and proposed solutions focus on C-string data, the concepts and ensuing discussions apply whenever a function returns local data by pointer or reference.
The problem with the above function is the scope of the C-string, name. It is defined and its memory allocated in get_name, making it a local variable in the function's scope. The function returns the variable's address, but the program deallocates the memory when the function returns. What happens to the deallocated memory depends on the program and the computer running it. The computer may reallocate the memory and overwrite its contents very quickly. However, the program that calls get_name is likely still using (or, more accurately, trying to use) the data stored in name. If the program runs correctly once, there's no guarantee that the next call will succeed. Even if the program consistently runs correctly on one computer, there's no guarantee it will work on another. The following figures illustrate three solutions.
Understand: scope != allocation
Although they are sometimes tightly coupled, scope and memory allocation are distinct concepts and mechanisms. Programs allocate and deallocate memory for local or automatic variables when they come into and go out of scope, respectively. In the case of local variables, the tight coupling of scope and memory management blurs the boundaries distinguishing them, making them appear as one. However, static variables, the first solution presented, make the distinction more apparent. Study each solution carefully to understand the interplay between scope and memory allocation.
Solutions And Outcomes
There isn't a single or even a best solution for the scoping problem. Each described solution has a set of unique outcomes that, if misunderstood, can lead to further failures. However, we shouldn't consider the outcomes as programming errors or language deficiencies, but as the result of our design choices. Various data structures, such as stacks, lists, and trees, are useful examples: some support efficient insertion, while others prioritize efficient searching. A common software development task is aligning a structure's behaviors with the needs of a given problem. As practicing computer scientists, our task is to understand the ramifications of each approach, enabling us to identify a satisfactory match for a given problem.
Returning local static data by pointer.
Programs allocate memory for static variables when the operating system loads them into memory, and that memory remains allocated until the program ends. The variable namedoes go out of scope when the function ends, but the memory it names remains allocated and dedicated to the program. Since the function returns the address of name, the data at that address is accessible indirectly through it. For example:
char* line = get_line();
cout << line[3] << endl;
The static data solution is relatively easy to understand and straightforward to use. Although rarely a liability, it does have some limitations. First, it uses more memory than non-static variables. Early programming languages like FORTRAN didn't have automatic variables; instead, programs allocated memory for all variables at load time. ALGOL introduced the concept and term "automatic variable," allowing equivalent programs written in ALGOL-derived languages to use less memory than those written in older languages. Making a variable static does increase the program's memory requirements, but not significantly.
Second, functions that have static variables cannot be recursive or reentrant. We briefly covered recursive functions in Chapter 6, and reentrancy is a property only needed by specialized functions, most often seen in operating systems, and beyond the scope of this course. Nevertheless, the final imitation is more concerning.
void client()
{
char* data;
data = get_name();
. . .
data = get_name();
. . .
}
A consequence of returning static data by pointer.
Each call to get_name returns the same address, the address of name. Therefore, each call to get_name overwrites the data stored by the previous call. Depending on how the client program uses the data, this version of get_name may work correctly, or it may have a logical error. Two scenarios illustrate two possible outcomes:
A client function calls get_name and processes the data (the ellipses) it returns. When the client finishes processing the data returned by the first call, it makes one or more subsequent calls. Critically, it must no longer need the data returned by the previous call. This scenario is correct, and represents the most common way programs use static variables.
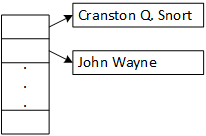
A less common scenario, and a logical error, is storing rather than processing the returned data. In this example, the client creates an array of character pointers and stores the data returned by get_name. However, each element of the array points to the same static memory location, the variable name, which only stores the last name the user enters.
Scenario (a) is more common than (b), making static data a good choice for solving the initial memory deallocation problem.
char* get_name(int size)
{
char* name = new char[size];
cin.getline(name, size);
. . .
return name;
}
(a)
(b)
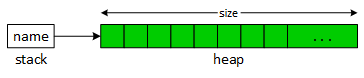
Returning dynamic data.
The new operator (green) allocates memory from the heap rather than the stack. Heap memory offers two distinct advantages: First, the program doesn't deallocate heap memory when the allocating function, get_name in this example, returns. Second, heap memory is more flexible than stack memory. Whereas programs must specify the size of stack memory with a compile time constant, programs can specify the size of heap data at runtime. This version of get_name capitalizes on this property by allowing the client program to specify the length of the allocated C-string.
Consequences of dynamic data.
Although managing the heap requires more effort than the stack, the effort is mostly hidden from programmers, with the benefits making the difference worthwhile.
Each call to get_name returns a different, unique address: the address of memory newly allocated by the new operator. Therefore, subsequent calls to get_name do not overwrite the data returned by the previous call. This behavior replaces the problem with static data presented above with the potential for creating a logical error.
The most common error occurs when programmers fail to deallocate heap memory when the program finishes using it, causing a memory leak. Remembering to delete heap memory before losing its address avoids the logical error.
Allocating a distinct C-string for each input operation solves the error illustrated in Figure 3(b), allowing the client program to read multiple strings before processing them.
Returning Calling-Scope Data
calling scope, local scope, scope, default arguments, function calls, convenience return value
The final solution solves the scoping problem by moving the data's definition, and therefore its scope, from the supplier to the client (i.e., the function calling the supplier). The client calls the supplier, passing the data by pointer. We can visualize a sequence of chained function calls as a path through a program. In this visualization, while one function calls another, the first remains "active" or running, and consequently, its local or automatic data remain allocated. The supplier accesses the client's data indirectly through its parameter.
void client()
{
char data[100];
.
.
,
get_name(100, data);
// use data
}
Receiving and returning calling-scope data.
Variable names follow the scoping rules: data is a local variable of client and inaccessible outside of it. Conversely, name is a get_name parameter - making it a local variable. The function call does not deallocate the data array, thereby solving the original problem by changing the scope in which the program defines and allocates the array's memory.
The client code, the code calling get_name, defines a character array on the stack and passes its address to get_name by pointer.
Although the variable named data is inaccessible in get_name, its memory is accessible through its address, passed to the parameter name.
When one function calls another, control shifts from the first to the second, but the first maintains its local variables while the second runs. When the second function ends, control returns to the first function.
The variable names, data and name, are local variables defined in and bound to client and get_name, respectively. However, name points to data, joining the variables while get_name runs.
Pass-by-pointer is an INOUT passing mechanism, making it unnecessary to get_name to return name. Function calling get_name can ignore the returned value, but it allows programmers to use the function call as an expression:
cout << get_name(data) << endl;
The C-string API provides examples of this convenience technique: see the standard versions of strcpy and strcat.
char* get_name(int size, char* name = nullptr)
{
if (name == nullptr)
name = new char[size];
cin.getline(name, size);
. . .
return name;
}
void client()
{
char* data = get_name(100);
// use data
.
.
.
.
}
void client()
{
char* data = new char[200];
get_name(200, data);
// use data
.
.
.
}
(a)
(b)
(c)
Combining calling-scope and dynamic data. At the expense of a modest increase in complexity, we can make get_name even more flexible. The client must specify the array's size, but the default argument makes passing data optional.
If the client allocates memory and passes it to get_name, the function will use it. But conveniently, the client can allow get_name to allocate and return the memory. The get_name parameter order must obey Default Argument Rule 1.
client doesn't allocate memory for data, accepting the default argument and allowing get_name to allocate it.
client allocates memory for data, passing it to get_name. The if-statement in get_name skips the memory allocation in this case.
In the first interview, I didn't see the problem right away and was admitting, "I don't see the problem," when I identified it. I continued, smoothly, I hoped, "unless you mean...," in a tone that, again, I hoped, suggested I had spotted the error right away but was looking for a more challenging problem.