Constructors are, first and foremost, just functions. They can range from simple to complex. However, constructors are special functions that are called automatically whenever a program creates (i.e., instantiates) a new object. The primary purpose of constructors is to construct or initialize an object. Visually, constructors are set apart from "regular" functions by two characteristics: (a) they have the same name as the class for which they are constructing objects, and (b) they do not have a return type.
Constructors
constructor, kinds of constructors, instantiate, prototypes
Constructors are an essential part of object-oriented programs. Categorizing and naming the categories makes it easier to describe and characterize them. However, the categories can overlap, so the primary distinction is how a program uses them.
Default
Conversion
Copy
Move
General
Constructor Prototypes
Constructor Calls
class Foo
{
public:
Foo();
Foo(int x);
Foo(int x, int y);
};
Foo f1; // (a)
Foo* f2 = new Foo;
//Foo f1();
//Foo* f2 = new Foo();
Foo f3(5); // (b)
Foo* f4 = new Foo(5);
Foo f5(5, 10); // (c)
Foo* f6 = new Foo(5, 10);
Overloaded constructors. Programs call a constructor whenever they instantiate an object. Like any overloaded function, the compiler binds the call to a specific function based on the arguments: the constructor function, whose parameter list matches the arguments in the function call, is selected to run.
Calls the default, no-argument constructor. Historically, a call to the default constructor did not allow parentheses, but a recent change to the ANSI C++ standard now permits them
Calls the one-argument constructor
Calls the two-argument constructor
Each constructor is designed to fill a specific programming need, but most classes will only need a few constructors - not all. The following sections describe each kind of constructor in detail, but the focus is on the constructor's visible operations. One object-oriented feature, polymorphism, requires that each object store a hidden pointer, called the vptr (virtual pointer). One of the tasks of every constructor is to initialize vptr, which it does by running code that the compiler automatically inserts into each constructor. If the class does not have any constructors, the compiler creates a simple default constructor to initialize the vptr. We'll explore polymorphism in more detail in a later chapter.
As described below, we typically distinguish constructors based on their parameters. However, we use the term "general constructor" to denote any constructor that doesn't fit into one of the other categories. Further confusing constructor identification, sometimes we need a general constructor having only one parameter, but we don't use it as a conversion constructor. Sometimes, the distinction between a general and conversion constructor depends on how we use it rather than the number of parameters. We'll see in the CString example later in the chapter that this can sometimes cause problems.
The Default Constructor
default constructor
The primary characteristic that sets a default constructor apart from the other constructors is that it has no parameters. A default constructor often creates an "empty" object or an initialized object with default values. Although the text didn't state it at the time, many of our previous examples have relied on the string class default constructor that creates a string object that does not contain any characters. We can also use a default constructor to create an "empty" instance of our Time class.
class Time
{
private:
int hours;
int minutes;
int seconds;
public:
Time() : hours(0), minutes(0), seconds(0) {}
};
class Time
{
private:
int hours = 0;
int minutes = 0;
int seconds = 0;
};
(a)
(b)
class Time
{
private:
int hours = 0;
int minutes = 0;
int seconds = 0;
public:
Time(int h, int m, int s)
: hours(h), minutes(m), seconds(s) {}
};
class Time
{
private:
int hours = 0;
int minutes = 0;
int seconds = 0;
public:
Time() {}
Time(int h, int m, int s);
};
(c)
(d)
Time t1;
Time* t2 = new Time;
Time t3(); // error
Time* t4 = new Time(); // okay
(e)
(f)
Default constructor examples. The examples illustrate programmers' options for initializing new objects with "empty" or default values and how those options have evolved. The semicolon, illustrated in (a) and (c), introduces an optional initializer list, detailed below.
C++ did not allow initializing data members in the class specification for much of its life. The compiler-created default constructor can allocate memory but not initialize it. Therefore, in the pre-2014 versions of C++, programmers were obligated to make a constructor to initialize member variables to default values (pink).
The ANSI 2014 standard added member initialization in the class specification (violet). In-class initialization is a compact, easily used notation for initializing data members to default values when the program instantiates a new object, often, but not always, eliminating the need for an explicit default constructor.
If programmers add a parameterized constructor (blue) to a class, they are saying, in a sense, "This is the only way you can create an instance of my class," preventing the compiler from creating a default constructor and rendering the in-class initializations superfluous.
Adding a "dummy" or do-nothing default constructor (green) allows programmers to instantiate an object without providing parameter values. In this case, the in-class initialization supplies the data member's initial values.
By eliminating the parentheses when calling a default constructor, C++ makes the defining syntax for objects the same as fundamental types:
int counter;.
Newer standards allow parentheses when the program creates an object with new.
Some software engineers maintain that every class should have a default constructor, and sometimes, a language feature may require one, or a program may need to create an "empty" object. However, in my opinion, class designers should generally be free to choose how programs instantiate their classes - provide a default constructor only if there is a legitimate purpose.
Conversion Constructor
conversion constructor
A conversion constructor typically has one parameter that it converts from the given type to an instance of the defining class (i.e., the class defining the constructor function). However, some conversion constructors do have multiple parameters, reinforcing the idea that we base the labels more on how we use and think about the constructor than on their parameter count. What the conversion means and how the conversion function works depends entirely on the source and destination types.
class Foo
{
.
.
.
public:
Foo(Bar b);
};
class Time
{
private:
int hours;
int minutes;
int seconds;
public:
Time(int s)
{
hours = s / 3600;
s %= 3600;
minutes = s / 60;
seconds = s % 60;
}
};
(a)
(b)
Conversion constructors.
The label "conversion constructor" captures two important aspects of this specialized function. First, it is a constructor whose primary purpose is to build or construct new objects. Like all constructors, it builds instances of its defining class. The "conversion" part of the label suggests the second significant aspect of the function: it converts data from one type to another. Conversion constructors can convert fundamental types like int or double to objects, or they can convert objects from one class type to another.
The typical conversion constructor pattern converts the parameter type, Bar, to the defining class type, Foo.
This example modifies the make_time function from the structure version of Time example, making it a conversion constructor. It converts an integer into an instance of the Time class (i.e., into a Time object).
Generally, for converting an object from one class type to another to make sense, the two types must be related or similar. For example, the statement, string s("Hello, World!");, converts the string literal, a C-string, to an instance of the string class. The beginning and ending types are different kinds of strings.
Copy Constructor
copy constructor
A copy constructor creates a new object by copying an existing object. C++ bases two critical and fundamental programming operations on the copy constructor:
Therefore, whenever programs pass objects to or return them from functions by value, they create new objects by calling the copy constructor to copy an object from one program scope to another. The pass and return operations are so fundamental to programming that the compiler automatically generates a copy constructor for every class. In the previous examples, the copy constructor was simple enough for the compiler to create it automatically. Later, we will see more complex situations where the compiler-generated copy constructor is insufficient, and in such cases, we must replace it with one we write. However, writing a copy constructor presents a problem: Since the copy constructor implements pass- and return-by-value, how can we write a copy constructor function without causing infinite recursion? Answering that question underscores the characteristic distinguishing a copy constructor - the characteristic necessary to override the compiler-generated copy constructor correctly. Copy constructors always have a single reference parameter of the defining class type:ClassName(const ClassName& o);
class Person
{
private:
int id;
int weight;
double height;
public:
Person(const Person& p);
};
Copy constructor example. The copy constructor's task is straightforward: copy each member variable in the existing object to the new object. The compiler-created copy constructor works for the Person class as specified here, but the overloaded version demonstrates a typical constructor's behavior and general pattern.
If any member variable is a pointer, the copy operation becomes more complex, and we defer dealing with that situation until the next chapter. For the curious or those facing a more immediate problem, please see The Copy Constructor in the next chapter.
fraction fraction::add(fraction f2)
{
int d = . . .;
int n = . . .;
return fraction(n, d);
}
(a)
(b)
A special case for returning objects. One of the copy constructor's tasks is returning objects from functions. Although the figure illustrates a special case, it often occurs, so the C++ compiler generates code implementing a modest return efficiency. The example makes three assumptions. First, a class named fraction. Second, the fraction class has two member variables named numerator and denominator. And last, the fraction class defines a member function named add that adds two fraction objects and returns a new fraction object representing the sum.
This version of the add function causes three implicit or "hidden" function calls. The first implicit call is to the default constructor (highlighted in yellow). The return statement (highlighted in orange) calls the copy constructor to return the object and a destructor to destroy temp.
The second version requires a general or parameterized constructor but saves two function calls. The object created in the return statement is constructed in the calling scope rather than the function's scope. So, this version does not make a destructor call and only makes one general constructor call (yellow).
Move Constructor
move constructor
Like the copy constructor, the move constructor can be identified by its distinctive parameter:
ClassName(ClassName&& o);
If a move constructor has additional arguments, they must have default values (i.e., default arguments). Unlike copy constructors, move constructors can take some or all the resources held by the argument object rather than copying them, leaving the original object in a valid but potentially incomplete state. The text only introduces the double ampersand, &&, denoting an r-value reference declarator, and the move constructor. You will revisit both in greater detail in the algorithms and data structures course.
General Constructor
general constructor
No special syntax or pattern defines a general constructor. A general constructor does not fit into any of the categories described above. So, any constructor that has two or more parameters is a general constructor just because it's not (a) a default constructor (no parameters), (b) a conversion constructor (has one parameter that's not a reference), or (c) a copy constructor (one parameter that is a reference). It is possible to convert the first make_time function from the struct Time example into a general constructor:
Time::Time(int h, int m, int s)
{
hours = h;
minutes = m;
seconds = s;
}
A general constructor. If it's not a default constructor, a conversion constructor, a copy constructor, or a move constructor, then it's a general constructor
Constructors: Initializer Lists, Data Flow, And Header Files
constructor, initializer list, data flow, header file
One common task of constructor functions is initializing (i.e., assigning the first or initial value to) an object's member variables, regardless of the constructor's overall complexity. Although programmers can initialize members in the constructor's body, most practitioners consider it better practice to use an initializer list. An initializer list is a compact notation equivalent to a sequence of assignment statements. However, they have the advantage of running before the constructor's body, so the member variables are ready to use as soon as the body runs. Initializer lists begin with a colon and appear between a function's parameter list and the body's opening brace. Initializer lists follow a simple pattern:
class fraction
{
private:
int numerator;
int denominator;
public:
fraction(int n, int d) : numerator(n), denominator(d) {}
};
Argument list notation. An argument list includes everything from the colon to (but not including) the opening brace of the empty function body. The symbols used in the initializer list are specific. The color coding shows the connections between the data members, the function arguments, and the symbols appearing in the initializer list.
Constructors are the only functions that may have an initializer list, and the list is a part of the constructor's definition. So, if the function is prototyped in the class but defined elsewhere, the initializer list appears with the definition.
An initializer list is a comma-separated list of initializer elements. Each element behaves like an assignment, so numerator(n) is equivalent to numerator = n. The color coding in the figure above highlights the connection between a constructor's arguments and member variables: the first part of each element is the name of a member variable, and the second part (enclosed in parentheses) is the name of one of the function's parameters. With one exception, the list elements may appear in any order. We'll explore that exception, inheritance, in the next chapter.
Works
Preferred
fraction::fraction(int n, int d)
{
numerator = n;
denominator = d;
int common = gcd(numerator, denominator);
numerator /= common;
denominator /= common;
}
fraction::fraction(int n, int d)
: numerator(n), denominator(d)
{
int common = gcd(numerator, denominator);
numerator /= common;
denominator /= common;
}
(a)
(b)
Initializer list vs. assignment: Member initialization. Constructors often initialize member variables with function arguments. Simple assignment statements work, but an initializer list is preferred. In this example, gcd is a function that calculates the greatest common divisor - the largest number that divides both function arguments evenly.
The constructor body has one assignment operation for each member variable and each constructor argument. I've deliberately written the function to emphasize the difference between the two illustrated techniques, but in fairness, we can simplify this version:
int common = gcd(n, d);
numerator = n / common;
denominator = d / common;
An initializer list (highlighted) behaves like a series of assignment operations but is preferred to the explicit assignment because it takes place before any statements in the constructor body run
Constructor data flow.
The initial data originates in the client program, passing from the constructor call arguments to the function's parameters. The function copies the parameter data into the object's member variables.
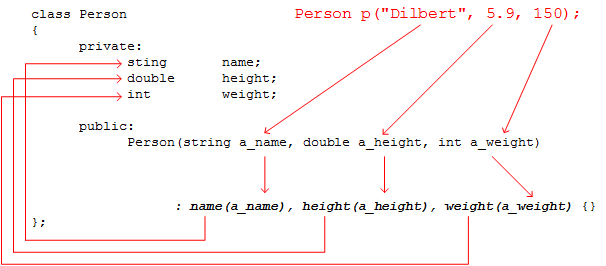
The variable p is an instance of class Person; when a program instantiates a class, it automatically calls a constructor function and passes the arguments, Dilbert, 5.9, and 150, to the constructor's parameters
The data from the constructor call is passed into the function's parameters, which are variables named a_name, a_height, and a_weight
The variable names in the function parameter list are used in the initializer list that appears on the right side of the colon
Each element of the initializer list consists of a member variable name followed, in parentheses, by the name of a constructor parameter
Every function must have exactly one body. The body is often empty for simple constructors whose only purpose is to initialize the object's member variables. In the following example, the {} at the end is the function's empty body and not part of the initializer list.
Initializer lists are a part of the function definition and not of the declaration or prototype. So, if the class only contains a function prototype and the function definition is in a separate .cpp file, then the initializer list goes with the function definition in the .cpp file:
.h File
.cpp File
class fraction
{
private:
int numerator;
int denominator;
public:
fraction(int n, int d);
};
fraction::fraction(int n, int d)
: numerator(n), denominator(d)
{
int common = gcd(numerator, denominator);
numerator /= common;
denominator /= common;
}
Using separate header and source code files. The figure illustrates the correct location of the initializer list when programmers separate the function definition from the prototype in the class specification.
Caution:
.h File
.cpp File
class fraction
{
public:
fraction(int n, int d) {}
};
fraction::fraction(int n, int d)
: numerator(n), denominator(d)
{
. . . .
}
A common error: Braces form a function body. It's a common practice to write constructors with initializer lists that only initialize member variables. So common is the practice that we can easily develop a habit of always putting braces at the end while forgetting that the braces form a function's body. But a function may only have one body. If we move the function definition, including its body, to a source code (.cpp) file, we must remember to end the prototype (in the header file) with a semicolon. The error shown here will result in a "multiple definition" diagnostic message.
Default Arguments
constructor, default arguments, header file
Although the UML has always permitted class designers to specify initial values for member variables and function arguments, C++ originally did not allow programmers to initialize member variables in the class specification. So, programmers initialized member variables with constructors, and you may still see examples of this in existing code. However, C++ has always supported default arguments, which may be used with any C++ function (not just constructors). When we use default arguments with constructors, they must follow all of the rules listed in Chapter 6 (and it's probably a good idea to review those rules now).
+fraction(n: int = 0, d : int = 1)
fraction(int n = 0, int d = 1);
(a)
(b)
Converting UML to C++. The UML provides a syntax for default arguments, which we can easily translate into C++.
The UML constructor
is translated into the C++ code
In "real world" C++ programs, it is common for the class specification to appear in a .h file and the member functions (including constructors) to appear in a .cpp file. When we follow this organization, there is one unfortunate aspect of initializer lists and constructor default arguments that we must memorize:
.h File
.cpp File
class fraction
{
private:
int numerator;
int denominator;
public:
fraction(int n = 0, int d = 1);
};
fraction::fraction(int n, int d)
: numerator(n), denominator(d)
{
int common = gcd(numerator, denominator);
numerator /= common;
denominator /= common;
}
(a)
(b)
Locating default arguments and initializer lists. Programmers frequently define small, simple functions inside the class specification. However, they usually separate larger, more complex functions into two parts, placing only a prototype in the class specification and defining the function in a separate source file. In the latter case, default arguments and initializer lists go to different locations.
Default arguments appear with the function PROTOTYPE in the header.(i.e., .h) file. This constructor may be called in one of three ways:
fraction(); // acts as a default constructor
fraction(n); // acts as a conversion constructor
fraction(n,d);
Initializer lists appear with the function DEFINITION in the source code (i.e., .cpp) file.
class fraction
{
private:
int numerator = 0;
int denominator = 1;
public:
fraction() {}
fraction(int n);
fraction(int n, int d);
};
Alternate member initialization. The ANSI C++ 2014 standard adds syntax to initialize member variables directly in the class specification. The initialization of numerator and denominator illustrated here is an alternative to using a constructor. In this example, a default constructor, which does nothing, is still required because the presence of the parameterized constructors prevents the client program from creating an empty fraction object. When programmers create one or more constructors, they say, "This is the only way you can create an instance of my class." An attempt to create an object in any other way is an error.
Default Constructors and In-Class Initialization
Replacing the constructor with initializations in the class specification is appropriate if a class only needs a constructor to initialize the member variables to the same value whenever the program creates an instance of the class. In that case, the compiler will automatically generate a default constructor to initialize the vptr as needed. However, initializing member variables inside the class specification doesn't always eliminate the need for a default constructor or default arguments. If the class defines one or more parameterized constructors, a default constructor or default arguments are necessary if the programmer allows client programs to create objects without supplying initializing data. For example:
fraction f1;
fraction* f2 = new fraction;
Furthermore, default object construction may require operations beyond simple member initialization.
Like any function, constructors can range from algorithmically simple to complex. Sometimes, complex constructors perform the same operations as simple ones, followed by additional operations befitting their complex nature. In many cases, we can avoid the overhead of writing and maintaining duplicate constructor code by putting the common, often simple, code in a basic constructor and allowing more advanced constructors to call it. Java has always supported in-class constructor chaining by using this(...) as the name of an overloaded constructor and with the number and type of arguments to differentiate between them. Before the adoption of the C++ 2011 standard, C++ did not permit in-class constructor chaining, but it does now, albeit with limitations.
Simple Constructor
class Table
{
private:
int rows;
int cols;
int** array;
};
Table(int r, int c) : rows(r), cols(c)
{
array = new int*[rows];
for (int i = 0; i < rows; i++)
array[i] = new int[cols];
}
(a)
(b)
Complex Constructor
Table(const Table& t) : Table(t.rows, t.cols)
{
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++)
array[i][j] = t.array[i][j];
}
Constructor chaining (aka constructor delegation).
In general, delegation describes the situation where one class or function relies on or assigns or passes some of its responsibilities to another class or function - it delegates some of its tasks to another class or function. Specifically, constructor delegation describes one constructor delegating or assigning some part of its tasks to another constructor in the same class - a complex constructor calls a simple one - the caller delegates some of its responsibility to the called function.
A class that implements a table as a two-dimensional array. rows and cols are the numbers of rows and columns in the table, respectively. array is a pointer to an array of pointers that make up the table rows.
A "simple" constructor that initializes the data members. The for-loop creates one table row per iteration. Note that the initializer list initializes rows and cols before the statements in the body of the constructor run.
A copy constructor implemented as a delegation constructor - it calls the simple constructor illustrated in (b), highlighted in yellow, to create a new Table object. The copy constructor copies the contents of the existing object, t, to the new or this object. Any constructor can delegate to another, so "delegation constructor" is not included in the named constructors above.
C++ imposes a severe restriction on delegation: it only allows one initializer in the initializer list. Assume for a moment that the Table class has a data member named member. Ordinarily, we could initialize member using the operation highlighted in coral. However, this results in a list with two comma-separated initializers, and the highlighted code is an error.
Chaining constructors works well when the operations of the called or delegated constructor (e.g., (b)) must or can run before the operations in the calling or delegating constructor (e.g., (c)). When that is not the case, the best we can do, in C++ or Java, is use a helper function to implement the common code.
display()
{
...;
...;
}
Window()
{
...;
display();
}
(a)
(b)
Window(int x, int y)
{
...;
display();
}
Window(int x, int y, int color)
{
...;
display();
}
(c)
(d)
Using a helper function to implement common constructor code. Helper functions reduce or eliminate the need to duplicate code across multiple functions. The example demonstrates using a helper function with constructors. However, unlike constructor delegation, we can use helpers anywhere the common operations are needed, and their benefit is proportional to the amount of common code. In this example, Window is the name of a class defining one helper and three constructors.
A helper function named display that displays a Window object. Programmers typically put helpers in the class's private section, so users cannot call them directly.
Creates a simple Window, perhaps using default values. The constructor displays the window following its initialization.
The user of the Window class specifies the coordinates of the upper left-hand corner of the window (x and y) when creating the object and then displays it.
In the final example, the constructor has three parameters: the location on the screen at (x,y) and the color of the window. Like the example (c), the helper function displays the window when its initialization is complete.